Spracovanie prirodzeného jazyka |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| ABSTRAKT
KĽÚČOVÉ
SLOVÁ ANALÝZA SYSTÉMY
PRE POCHOPENIE
|
Bc. Marek Trabalka trabalka@decef.elf.stuba.sk Katedra informatiky a výpočtovej techniky Fakulta elektrotechniky a informatiky Slovenskej technickej univerzity November 1998 Hlavný zdroj: Turban, E.: Expert Systems and Applied Artificial Intelligence. Maxmillan Publishing Company 1992.
AbstraktPrezentovaný článok poskytuje čitateľovi základný prehľad o systémoch spracovania prirodzeného jazyka. Vysvetlené sú dva najčastejšie používané prístupy. Koncept analýzy kľúčových slov je založený na kľúčových slovách zo špecifickej aplikačnej oblasti a na slovách zvlášť zaujímavých pre analyzovaný jazyk. Tieto slová sa hľadajú vo vstupe od užívateľa a podľa toho, ktoré sa nájdu, systém poskytne špecifický výstup. Hlavný dôraz článku však spočíva na popise druhého prístupu - syntakticko-sémantickej analýze textu. Najprv je uvedený stručný úvod do jazykovednej teórie. Potom je vysvetlená základná schéma analyzátora, ktorá obsahuje päť základných častí systému. Tieto časti sú modul pre parsovanie, slovník, modul pre porozumenie, báza znalostí a generátor výstupov. Každý modul je samostatne popísaný v texte. Na záver je uvedený stručný zoznam aplikácií systémov pre spracovanie prirodzeného jazyka v praxi. Kľúčové slováprirodzený jazyk, syntax, sémantika, kľúčové slová
AbstractPresented article gives a reader basic overview of natural language processing systems. The two mostly used approaches are explained. Concept of keyword matching is based on analysis of domains/task specific keywords and some additional words with a special meaning in a language. These words the user input is scanned for and appropriate output is then produced. But main accent of article laid on second approach - syntactic and semantic analysis of a text. Firstly general introduction into linguistic terminology and concepts is included. Then there is a general block-diagram of analyzer system that shows five basic blocks natural language processing system consists of. These blocks are parser, lexicon, understander, knowledge-base and generator. Every block is separately described in a text. Finally, brief enumeration of possible applications of the natural language processing system is listed. Keywordsnatural language, syntax, semantics, keywords
ÚvodSpracovanie prirodzeného jazyka sa zaoberá komunikáciou človeka s počítačom pomocou prirodzeného jazyka, napr. angličtiny či slovenčiny, namiesto používania špeciálnych príkazov, menu a symbolov. Pri riešení tohto problému sa využívajú nielen poznatky z počítačovej vedy, ale samozrejme z oblasti jazykovedy ale taktiež aj psychológie. Spracovanie prirodzeného jazyka (NLP - natural language processing) je po expertných systémoch najväčšou aplikáciou umelej inteligencie. Aby sme dnes mohli používať počítač, musíme sa naučiť množstvo príkazov, počítačových jazykov a spôsobov manipulácie s programami. To všetko vyžaduje veľa času a úsilia. A to je taktiež hlavný dôvod, prečo sú počítače považované za neprívetivé. Samozrejme, dotykové obrazovky, svetelné perá a tablety pomáhajú zjednodušiť ovládanie, ale ani tie nie sú pre človeka celkom prirodzené. Keby sme mohli pri práci s počítačom používať náš jazyk, veľa problémov by ustúpilo do pozadia. Nepotrebovali by sme žiadne kurzy na prácu s počítačom, jednoducho by sme mu napísali (či povedali) čo chceme. Počítač by nám taktiež mohol pomôcť pri riešení tzv. informačného preplnenia, keby dokázal inteligentne filtrovať správy a informácie, ktoré nás denne zaplavujú. Hlavné využitie sa črtá najmä pri rozhraní k databázam a expertným systémom, kde by sme otázky mohli zadávať jednoduchšie a aj výsledky by nám boli prezentované zrozumiteľnejšie. Aby však počítač mohol pochopiť otázku v prirodzenom jazyku, musí mať dostatok vedomostí na analýzu a interpretáciu vstupu. Musí mať množstvo všeobecných znalostí o svete, ale taktiež špecifický slovník pre oblasť, v ktorej sa systém používa. Keď sa počítaču podarí zanalyzovať vstup, obvykle produkuje nejaký výstup. Obvykle výstup tvoria sekvencie viet či dlhších textov, ktoré sú dopredu zadané programátorom. Počítač znalý jazyka by však vedel poskytnúť plnohodnotný inteligentný výstup v ucelenej forme textu.
O jazykuJazyk predstavuje spôsob komunikácie. Zahŕňa ako verbálnu tak aj písomnú formu, ktoré nám pomáhajú vyjadriť naše myšlienky, túžby a pocity. Jazyk používa širokú škálu zvukov, znakov a symbolov na vytváranie slov, viet a odstavcov. Väčšina prirodzených jazykov nebola objavená ani vyvinutá, ale sa postupne vyvíjala počas storočí a svojim vývojom sa prispôsobovala meniacim sa podmienkam v spoločnosti.
Ako pracujú programy na spracovanie prirodzeného jazykaAko dokáže počítač pochopiť vstup v prirodzenom jazyku, dať ho do súvisu s kontextom a urobiť požadovanú akciu? V zásade sa v programoch používajú hlavne dva prístupy riešenia a to hľadanie kľúčových slov a syntakticko-sémantická analýza. Tretí prístup ktorý sa používa zriedkavejšie sa nazýva koncepčná závislosť. V tomto článku si rozoberieme prvé dva prístupy. Analýza kľúčových slovPrvé programy na spracovanie jazyka pracovali na základe analýzy kľúčových slov. Takýto program hľadal vo vstupnom reťazci kľúčové slová a frázy. Program bol schopný identifikovať, či “spoznať”, iba vybrané slová a frázy. Keď program rozpoznal nejaké slovo, vykonal podľa toho príslušnú špecifickú akciu. Prípadne mohol program vykonštruovať odpoveď na základe čiastočného kopírovania kontextu kľúčového slova zo vstupu. Program rozozná špecifický vstup, ktorý potom použije na tvorbu výstupného textu alebo spustenie nejakej akcie.
Proces analýzyNa obrázku je zobrazená schéma postupu programu pri analýze prirodzeného jazyka pomocou kľúčových slov.
Potom program hľadá v zadanom texte nejaké kľúčové slovo zo svojho slovníka slov prípadne fráz pomocou procesu hľadania vzorov (pattern-matching). Každé slovo či slovné spojenie, ktoré má program rozpoznávať, musí v ňom byť vopred uložené. Pretože chceme, aby program vedel reagovať na ľubovoľnú formu otázky, musíme uložiť všetky potenciálne variácie slova na jeho rozoznanie, prípadne aj jeho synonymá. Napríklad kľúčové slovo môže byť otec. Ale keďže ľudia volajú otcov rozličnými inými menami, musíme dať do slovníka aj slová tatko, tato, oco a pod. Program zozbiera kolekciu všetkých kľúčových slov, ktoré sa mu podarilo nájsť. Ak program nenájde v texte žiadne kľúčové slovo, jednoducho vyhlási, že nerozumie textu. Ak sa však podarilo nájsť nejaké kľúčové slovo či slová, program pomocou nich vykonštruuje výsledok. Je viacero možností ako to urobiť. Najjednoduchšou možnosťou je každému kľúčovému slovu priradiť výstupný text programu. Obvykle však program ešte vykoná nejaké ďalšie spracovanie pomocou ktorého vytvorí výstupný reťazec. Napríklad môže použiť časť vstupného textu, či už slovo alebo frázu, ktorú si zapamätá a potom skombinuje s naprogramovanou časťou a vytvorí tak celú vetu. Alebo môže urobiť špeciálne spracovanie v prípade istých kľúčových slov, napr. pri nájdení zámena ja, môj ho nahradí zámenom ty, tvoj, čím vytvorí dojem pochopenia osoby a zachová logiku zámena vo vzťahu k vám.
|
 Program obvykle začne zobrazením určitého hlásenia na
obrazovke na vybudenie užívateľa ku zadaniu vstupu. Keď ho užívateľ zadá, program
si ho uchová do pamäte.
Program obvykle začne zobrazením určitého hlásenia na
obrazovke na vybudenie užívateľa ku zadaniu vstupu. Keď ho užívateľ zadá, program
si ho uchová do pamäte.| Ahoj. Porozprávaj mi niečo o svojom probléme. Môj problém je umelá inteligencia. Tvoj problém je umelá inteligencia? Zaujímavé. No, v skutočnosti mám problémy s časťou UI o porozumení prirodzeného jazyka. Nie som si istá, či celkom rozumiem. To je práve ten problém, dokázať, aby program rozumel. Prosím, pokračuj To je zdroj môjho problému. Prečo hovoríš tvojho problému? Ono to nie je výhradne iba môj problém, ale teraz ma trápi. Má skutočnosť, že tvoj problém je výhradne, niečo spoločné s tebou? Určite má. Čo to pre teba znamená? Veľa. Zdá sa mi, že sa vyhýbaš rozhovoru o tvojich rodičoch. Čo s tým majú preboha spoločné moji rodičia? Predtým si spomenul tvoj problém. To hej. Zdá sa, že začínaš uvažovať pozitívne. ... |
Na tomto príklade vidno silné aj slabé stránky programu. Dialóg naozaj zdanlivo pôsobí rozumne, ale vidno isté problémy pri porozumení, napr. pri otázke s vyznačeným slovom výhradne, kde si ELIZA myslela, že problémom je výhradne.
ELIZA má na každé kľúčové slovo viacero odpovedí, ktoré voľne obmieňa pri používaní. Ak sa jej nepodarí rozoznať žiadne kľúčové slovo, povie niečo neutrálne charakteru “To je zaujímavé” alebo “Len pokračuj”. Samozrejme ELIZA pozná základné triky s anglickými zámenami I / You a dokáže transformovať vaše vety na otázky. Dokáže dokonca uchovať nejaké slovo či frázu a použiť to potom neskôr pri zmene témy. Tým budí dojem istej inteligencie, pretože si dokáže niečo zapamätať a neskôr to použiť. Často takto odpamätané veci použije celkom rozumne, pokiaľ ste medzitým nezmenili úplne tému rozhovoru.
Program má jednu zaujímavú vlastnosť: čím viac mu dôverujete, tým lepšie dáva výsledky. Pokiaľ sa ho budete stále nezmyselne pýtať, nebude sa chovať rozumne, ale pokiaľ s ním budete komunikovať naozaj ako so psychiatrom, potom môže byť výsledok až prekvapivo realistický.
Neskôr bolo vytvorených veľmi veľa variácií tohto programu. Napriek tomu, že program rozhodne nemožno považovať za inteligentný, jeho užitočnosť pre ďalší vývoj bola veľmi veľká. Ukázal, že kľúčové slová môžu byť veľmi silným a praktickým nástrojom.
Veľmi dôležitou vlastnosťou pri týchto programoch sa javí najmä veľkosť slovníka, ktorý, ako sme už spomenuli, musí obsahovať všetky slová, ktoré majú byť rozoznané. Toto je veľkým problémom pri programoch na všeobecné účely, ale nemusí byť až tak veľmi limitujúce pri užívateľskom rozhraní nejakej konkrétnej aplikácie. Preto zrejme aj tieto jednoduché formy spracovania prirodzeného jazyka majú v praxi svoje opodstatnenie.
Syntaktická a sémantická analýza
Napriek tomu, že prístup pomocou kľúčových slov je často používanou technikou pri spracovaní jazyka, jeho užitočnosť a použitie je značne limitované, pretože nedokáže chápať najrozličnejšie variácie, ktoré sa v jazyku bežne objavujú. Práve toto bol dôvod, prečo sa začali hľadať inteligentnejšie spôsoby analýzy textu v prirodzenom jazyku a jeho pochopenia.
Najpriamejším a najobvyklejším prístupom je vykonanie detailnej jazykovednej analýzy vstupu. Pomocou takéhoto analytického prístupu je možné pre počítač naozaj pochopiť vetu a jej význam. Nanešťastie aj tento prístup má silné obmedzenia, ktoré vyplývajú najmä z povahy a čŕt prirodzeného jazyka. Zrejme najväčším problémom jazyka je, že v ňom neexistuje jednoznačný vzťah medzi výrazom a významom. Táto vlastnosť sa prejavuje dvomi formami: ako homonymia a ako synonymia. Druhou vlastnosťou jazyka je jeho takmer nekonečná možnosť kombinovania prvkov medzi sebou, napríklad spájanie slov do viet. Napokon aj obrovský rozsah slovnej zásoby nepriaznivo vplýva najmä na rýchlosť analýzy a náročnosť prípravy slovníkov. V nasledujúcej tabuľke je príklad, ako možno jednu a tú istú vec vyjadriť rozličnými spôsobmi.
| Koľko priamych letov je medzi Bostonom a Fénixom? Máte nejaké priame lety medzi Bostonom a Fénixom? Rád by som letel z Fénixu do Bostonu bez medzipristátia. Ktoré lietadlá letia z Fénixu do Bostonu bez zastávky? Potrebujem priamo letieť do Bostonu z Fénixu. |
Samotná analýza prirodzeného jazyka sa dá rozdeliť na viacero rovín:
- fonologická analýza sa zaoberá rozborom zvukového vstupu a jeho transformáciou do elektronického textu; toto je obvykle riešené samostatným programom
- morfologická analýza sa zaoberá analýzou tvaroslovia pomocou ktorej sa snaží identifikovať gramatické kategórie jednotlivých slov
- syntaktická analýza identifikuje vetné členy vo vete a ich skladbu do fráz
- morfematická analýza dopĺňa morfologickú a syntaktickú analýzu rozborom morfologickej stavby slov a identifikáciou významu morfém v slovách
- sémantická analýza sa zaoberá rozborom významových častí vo vete a identifikáciou sémantických pádov
- kontextová analýza napokon dáva vetu do súvislosti s kontextom
Význam jednotlivých rovín analýzy sa dá výborne ukázať pomocou chybného textu, ako vidno na nasledujúcej tabuľke.
Čřvskmn iděe math nosss d ’ lha. |
Fonologicky nesprávne |
Červenskami ideova matý nosník prídlžie |
Morfologicky nesprávne |
Červenými ideou mať nos dlhý. |
Syntakticky nesprávne |
Červené idey majú dlhé nosy. |
Sémanticky nesprávne |
Červené žaby majú dlhé nosy. |
Pragmaticky nesprávne |
Zelené žaby žijú v rybníku. |
Správne |
Systémy pre spracovanie prirodzeného jazyka málokedy implementujú všetky tieto roviny. Fonologická rovina býva obvykle riešená úplne nezávisle, programami na rozpoznávanie hlasu. Morfologická a morfematická rovina sú často spracovávané značne zjednodušene, pretože daný jazyk (typicky angličtina) má relatívne jednoduchú morfológiu. Kontextová analýza je taktiež častokrát neúplná či celkom chýba, najmä ak postačuje spracovanie jednotlivých viet osobitne.
Napriek všetkým problémom, ktoré pri jazykovednej analýze existujú, prakticky všetky existujúce analyzátory dosahujú rádovo lepšie výsledky než programy pracujúce pomocou kľúčových slov.
Základné jazykové jednotky
Predtým, než začneme podrobnejšie rozoberať prácu analyzátorov, je vhodné objasniť si niektoré pojmy z jazykovedy.
Základnou stavebnou jednotkou jazyka je veta. Veta ako taká môže vyjadrovať myšlienku, názor, pocit, príkaz či otázku. Veta sa skladá zo slov. Slová ako také majú nejaký samostatný význam, ale ich hlavná sila spočíva práve v možnosti ich spájania do fráz a viet, ktoré sú potom schopné vyjadriť ucelenejší obraz myšlienok.
Slová sa obvykle rozdeľujú do viacerých skupín, podľa ich jazykovedného významu. Toto delenie sa môže mierne líšiť pre rôzne jazyky. Slovné druhy pre slovenčinu a angličtinu sú uvedené v nasledujúcej tabuľke
| SLOVENČINA | ANGLIČTINA | VÝZNAM |
| podstatné mená | nouns | označujú osoby, zvieratá, veci |
| prídavné mená | adjectives | slúžia na modifikáciu a upresňovanie podstatných mien a zámien |
| zámená | pronouns | zastupujú podstatné mená, majú referenčnú funkciu |
| číslovky | označujú číselný počet, poradie | |
| slovesá | verbs | vyjadrujú nejaký dej alebo stav vecí |
| príslovky | adverbs | slúžia na modifikáciu významu slovies |
| predložky | prepositions | vyjadrujú vzťah medzi menným objektom a iným slovom vo vete |
| spojky | conjunctions | majú význam spojovacích článkov medzi slovami, frázami a vetami |
| častice | sú pomocné slová vo vete | |
| citoslovcia | interjections | vyjadrujú náladu, city |
| determiners | upriamujú pozornosť na podstatné meno |
Nielen pri slovenčine či angličtine, ale pri väčšine jazykov sa môžeme stretnúť s tzv. tvarovou homonymiou, keď jedno slovo môže mať dva rôzne tvary odlišných slovných druhov, napr. slovo mať, ktoré môže predstavovať podstatné meno aj sloveso. Takéto slová spôsobujú počítačom nemalé problémy pri analýze vety.
Každý jazyk má vytvorený komplexný systém, ktorý určuje, ako je možné spájať jednotlivé slová tak, aby vytvorili vety. Tento systém pravidiel sa súhrnne nazýva gramatika. Bližší pohľad na stavbu vety bude uvedený neskôr, pri opise modulu pre parsovanie.
Morfémy
Pri analýze vety programy začínajú jej rozdelením na samostatné slová. Kvalitné analyzátory však idú ešte ďalej a rozdelia slová na tzv. morfémy. Morféma je najmenšia jazyková jednotka, ktorá má nejaký jazykový význam. Morfémy sa v rôznych jazykoch rôzne líšia. Hlavnými typmi morfém sú gramatické, koreňové a derivačné. Koreňové morfémy tvoria jadro slova (napr. žen-a). Gramatické morfémy vyjadrujú gramatické vlastnosti slova (napr. stroj-ný). Derivačné morfémy slúžia na obohacovanie slovnej zásoby pomocou odvodzovania slov (napr. do-robiť). Každé slovo má aspoň jednu koreňovú morfému a prípadne aj nejaké iné.
Rozoberaním slov na morfémy sa zaoberájú morfologická a morfematická analýza. Potreba takýchto analýz silne závisí od jazyka. Napr. angličtina má pomerne jednoduchú a pravidelnú morfológiu, ktorej sa preto nevenuje príliš veľká pozornosť v programoch. Vzťahy medzi slovami sú vyjadrené najmä slovosledom. Naproti tomu napr. slovenčina (a všetky slovanské jazyky) patrí do skupiny tzv. flektívnych jazykov a má veľmi bohatú a rôznorodú morfológiu. Práve morfémami sa tu primárne vyjadrujú vzťahy medzi slovami vo vete a preto pri slovenčine má morfologická aj morfematická analýza veľký význam.
Systémy pre pochopenie prirodzeného jazyka
Na obrázku je znázornená základná schéma programu pre pochopenie prirodzeného jazyka.

Modul pre parsovanie
Kľúčovým prvkom v systémoch prirodzeného jazyka je parser. Parser je časť softvéru, ktorá analyzuje vstupnú vetu po syntaktickej a morfologickej stránke. Má za úlohu rozobrať vetu na slová a následne z nich vytvoriť tzv. parsovací strom.
Celý parsovací proces je podobný tomu, ktorý sa učí v školách ako gramatický rozbor vety. Parser identifikuje mennú a slovesnú časť vety, ktoré potom ďalej rozdelí na jednotlivé vetné členy. Táto syntaktická analýza je prvým krokom ku pochopeniu zmyslu vety.
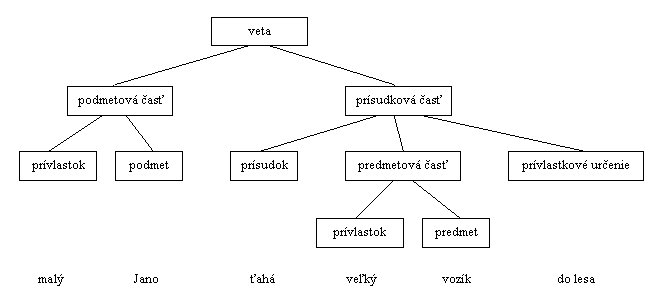
Priebeh analýzy vychádza samozrejme z jazykovedných poznatkov. Veta sa skladá z podmetovej a prísudkovej časti, teda
veta = podmetová časť + prísudková časť
Podmetová časť sa môže skladať z jednoduchého podmetu, ale obvykle ho dopĺňa jeden či viac prívlastkov.
podmetová časť = prívlastok + podmet
Prísudková časť sa skladá z prísudku a obvykle aj z predmetu a príslovkového určenia.
prísudková časť = prísudok + predmetová časť + príslovkové určenie
Samozrejme, v reáli tu existuje veľmi veľa iných variácií, toto bol iba základný náčrt stavby vety
Úlohou parsera je každému slovu vo vete nájsť funkciu vetného člena a vytvoriť parsovací strom tak, aby boli všetky slová navzájom pospájané tým správnym spôsobom. Na obrázku je príklad rozparsovania vety Malý Jano ťahá veľký vozík do lesa.
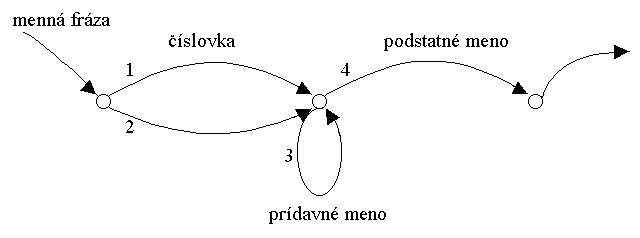
Často používanou metódou pri parsovaní sú tzv. rozšírené prechodové siete (ATN - augmented transition networks). Takáto sieť má diskrétne stavy, ktoré sú pospájané pomocou oblúkov. Oblúky reprezentujú podmienky, ktoré musíme splniť, keď chceme prejsť z jedného stavu do druhého. Nasledujúci obrázok ukazuje ako príklad definíciu mennej frázy, ktorá môže pozostávať z voliteľnej číslovky, z niekoľkých prídavných mien a z podstatného mena.
Slovník
Parsovací modul pri syntaktickej analýze nevyhnutne pracuje so slovníkom. Slovník obsahuje všetky slová, ktoré má program vedieť rozoznať. Slovník typicky obsahuje ako všeobecnú časť, tak aj časť špecifickú pre aplikačnú oblasť systému. Slovník môže obsahovať rôznorodé informácie, napr. správnu výslovnosť slova, rozdelenie slova na slabiky či gramatické a sémantické vlastnosti. Sofistikovanejšie systémy sa dokážu vyrovnať aj s homonymiou slov, kedy rozlišujú jednotlivé významy podľa spojenia slova s inými slovami vo vete. V takomto prípade bývajú v slovníku všetky rozpoznávané významy reprezentované oddelene. Slovníky môžu potom obsahovať aj väzby medzi synonymami - slovami s rovnakým významom ale rôznym tvarom.
Niektoré parsovacie moduly vykonávajú aj morfematickú analýzu, pri ktorej rozdeľujú slová na jednotlivé morfémy. V takomto prípade slovník obsahuje rozličné morfémy, ktoré sa v jazyku vyskytujú. V tomto prípade je možné neskôr lepšie analyzovať význam slova. Na druhej strane, veľa NLP systémov nerobí morfematickú analýzu a jednoducho majú v slovníkoch uvedené všetky možné varianty toho-ktorého slova. Táto druhá možnosť je pochopiteľne možná iba pri jazykoch s jednoduchou morfologickou stavbou, ku ktorým patrí napríklad aj angličtina. Pri slovenčine by takýto spôsob neprichádzal do úvahy, pretože objem slovníka by sa zväčšil až 40-násobne [Páleš, 1993]. Preto pri slovenčine a ostatných flektívnych jazykoch musí systém nevyhnutne vykonávať morfologickú a morfematickú analýzu.
Parser a slovník spoločne rozčleňujú vetu a vytvárajú parsovací strom - dátovú štruktúru, ktorá umožní extrahovanie skutočného významu vety.
Parser ako taký pracuje hlavne na základe porovnávania vzorov. Keď nájde jednotlivé slovo, hľadá ho ako vzor v slovníku. Keď sa ho tam podarí nájsť, uloží sa nabok, spoločne s informáciami, ktoré boli ku slovu v slovníku naviazané, ako napríklad slovný druh či rozdelenie na slabiky. Parser v spolupráci so slovníkom vie často odhaliť aj chyby v pravopise. Obvykle odhalí chyby spôsobené preklepom. Takto poškodené slová porovnáva opäť so slovníkom a hľadá k nim najpodobnejšie slovo.
Keď parser takýmto spôsobom pohľadá všetky slová v slovníku, začne konštruovať parsovací strom. Treba si uvedomiť, že aj po vytvorení parsovacieho stromu počítač stále vete nerozumie. Práve na tento účel slúži ďalší krok analýzy - sémantická analýza.
Modul pre porozumenie a báza znalostí
Sémantickú analýzu vykonáva modul pre porozumenie v súčinnosti s bázou znalostí. Cieľom tejto analýzy je určiť význam vety. Bázu znalostí môžeme konceptuálne rozdeliť na dve časti: všeobecnú bázu znalostí (obsahuje všeobecné poznatky o svete a základné lingvistické poznatky) a bázu znalostí špecifickú pre problémovú oblasť (obsahuje poznatky, procedúry a entity dôležité pre úlohy, na ktoré je aplikácia určená).
Na pochopenie významu vety musí systém disponovať znalosťami o slovách a spôsoboch, akým sa spájajú, aby vytvorili zmysluplný výrok. Hlavnú zásluhu na kvalite celého systému má preto jednoznačne báza znalostí. Úlohou modulu pre pochopenie je potom využiť parsovací strom na referencovanie bázy poznatkov.
Modul pre porozumenie vie odpovedať na užívateľove otázky dopytom nad bázou znalostí. Ak je vstupom výrok, modul pochopí jeho význam pomocou významov slov a fráz vysvetlených v báze znalostí a môže následne výrok zahrnúť do svojich poznatkov.
Modul pre porozumenie je vlastne typický expertný systém. Spoločne s bázou poznatkov môžu teda byť rozlične implementovaný, či už pomocou pravidiel, rámcov alebo sémantických sietí.
Generátor výstupov
Úlohou generátora je na pochopený vstup vytvoriť užitočný výstup. Ako svoj vstup používa dátovú štruktúru, ktorú vytvoril modul pre pochopenie významu. Táto štruktúra môže byť potom využitá na vykonanie dodatočných akcií. Keďže NLP systémy sú používané hlavne ako front-end rozhranie softvérových systémov, typickým výstupom je sada kódov príkazov pre výkonnú časť systému. Môže to byť priamo vykonanie nejakého príkazu. Pri databázových systémoch generátor vytvorí program v dopytovom jazyku, napr. SQL, a iniciuje hľadanie požadovanej informácie.
V najjednoduchších prípadoch generátor vypíše štandardný, dopredu špecifikovaný text na základe významu, ktorý pochopil z užívateľovho vstupu. Pochopiteľne, inteligentnejšie programy produkujú svoje vlastné texty, ktoré vykonštruovali na základe užívateľovho vstupu a svojich jazykovedných poznatkov.
Súčinnosť
Veľa programov pracuje tak, ako bolo znázornené v schéme pre spracovanie prirodzeného jazyka. Najprv teda urobia syntaktickú analýzu, vytvoria parsovací strom a potom pomocou neho urobia sémantickú analýzu.
Výskumy a experimenty však ukázali, že omnoho vyššiu výkonnosť dosahujú systémy, ktoré nemajú tieto fázy takto striktne oddelené, ale ich moduly pracujú navzájom paralelne. Dôvod je jednoduchý: sémantika dokáže často pomôcť vyriešiť nejednoznačnosť syntaxe ešte predtým, než je celá veta rozanalyzovaná. Takéto integrované systémy majú teda rovnakú štruktúru, ale spôsob práce je založený na obojstrannej komunikácii na báze slov. Tieto systémy lepšie chápu vstupy a rýchlejšie ich analyzujú.
Využitie
Po náčrte systémov pre spracovanie prirodzeného jazyka nám pochopiteľne vyvstáva jedna základná otázka: Na aký účel môžeme tieto systémy využiť?
Využitie inteligentných systémov, ktoré dokážu pochopiť prirodzený jazyk je veľmi rôznorodé. V prvom rade je tu priamo oblasť spracovania textov, kde sa NLP systémy využívajú na preklad z prirodzeného jazyka do iného prirodzeného jazyka, preklad z jedného počítačového jazyka do iného počítačového jazyka, na rozbor a kontrolu gramatiky a na prácu s dokumentmi (vytváranie abstraktov z textov, koncipovanie listov, inteligentné hľadanie a pod.).
Druhou významnou oblasťou je využitie NLP systémov vo forme rozhraní k iným softvérovým nástrojom. Veľmi časté je vytvorenie rozhrania v prirodzenom jazyku ku databázovým systémom a ku expertným či znalostným systémom, kde slúžia ako front-end rozhranie pre užívateľa.
Napokon sa tieto systémy využívajú v súčinnosti so systémami na rozpoznávanie hovorenej reči či písaného písma, kde poskytujú silnú podporu pri riešení konfliktov, chýb a neurčitostí.
Záver
Spracovanie prirodzeného jazyka je veľmi komplexnou a komplikovanou úlohou. Napriek veľkému nasadeniu sú výsledky dosahované v tejto oblasti stále pomerne slabé. Napriek tomu sa vo výskume a vývoji neustále pokračuje a očakáva sa, že úspešné zvládnutie problému porozumenia prirodzenému jazyku pomôže odstrániť veľa problémov súvisiacich s komunikáciou človeka a počítača a prispeje tak k ďalšiemu prudkému nárastu popularity výpočtovej techniky.
Literatúra
Mařík, V., Štěpánková, O., Lažanský, J. a kol.: Umělá inteligence 2. Praha, Academia 1997.
Mistrík, J.: Moderná slovenčina. Bratislava, SPN 1993.
Páleš, E.: Sapfo. Parafrázovač slovenčiny. Bratislava, SAV 1993.
Shinghal, R.: Formal Concepts in Artificial Intelligence. Fundamentals. London, Chapman & Hall 1992.
Turban, E.: Expert Systems and Applied Artificial Intelligence. Maxmillan Publishing Company 1992.