Techniky dolovania údajov
Pavol Boďo
Katedra informatiky a výpo .tovej techniky,
Fakulta elektrotechniky a informatiky,
Slovenská technická univerzita, Bratislava
Email: bodop@decef.elf.stuba.sk
Abstrakt. Tento článok pojednáva o technikách dolovania údajov. Stručne sa zaobrerá modelovaním vychádzajúcim
z teórie a podrobnejšie modelovaním vychádzajúcim z údajov. Z techník modelovania vychádzajúceho z
teórie sú popísané korelácie, t-testy, ANOVA, linerána a logistická regresia, diskriminantná
analýza a metódy predpovedania. Z techník modelovania vychádzajúceho z údajov sú rozobraté
zhluková analýza, faktorová analýza, rozhodovacie stromy, vizualizácia údajov, neurónové siete,
asociačne pravidlá a pravidlová indukcia.
Viaceré z týchto techník sú implementované do aplikácií na dolovanie údajov.
Najznámejšie z nich sú popísané a taktiež sú vyzdvihnuté ich prednosti.
V závere si povieme o novo vzniknutej metodológii CRISP-DM, čo je priemyselný štandardný proces pre
dolovanie údajov.
Abstract. This article considers Data Mining Techniques. It shortly deals with theory-driven modeling
and in detail with data-driven modeling. From theory-driven techniques are described correlations, t-tests, ANOVA, linear
and logistic regression, discriminant analysis and forecasting methods. From data-driven techniques
are discribed cluster analysis, faktor analysis, decision trees, data visualization, neural networks,
association rules and rule induction.
Some of these techniques are implemented into Data Mining Applications. The most common from them
are described also with their important advantages.
Finally, we will consider the new founded CRISP-DM methodology, which is CRoss Industrial Standard Process for
Data Mining.
Kľúčové slová:
dolovanie údajov, korelácia, t-test, ANOVA, lineárna regresia, logistická regresia, diskriminantná
analýza, metóda predpovedania, zhluková analýza, faktorová analýza, rozhodovací strom,
vizualizácia údajov, neurónová sieť, asociačne pravidlo, pravidlová indukcia, CRISP-DM.
Obsah
V súčasnosti sa zbiera a eviduje veľké množstvo údajov. Tento zber prebieha
vo veľmi rôznych oblastiach ako sú chemické a farmaceutické odvetvie, bankovníctvo,
obchod, telekomunikácie, štátna správa a v mnohých ďalších. Štátna správa je jedným
z najväčších zberateľov informácií, či už sa jedná o daňové priznania, colné deklarácie
alebo žiadostí o sociálnu podporu. V obchodoch sa evidujú nákupné koše jednotlivých
zákazníkov. Vydávajú sa aj špeciálne nákupné karty, z ktorých pre zákazníka vyplývajú
zľavy na tovary a pre obchod evidencia zákazníkov spolu s väzbou na ich nákupy.
V telekomunikáciách sa evidujú jednotlivé hovory a časy i miesta kde sa uskutočnili.
Všetky tieto údaje sú dôležité na tvorbu rôznych akcií, špeciálnych balíčkov (v obchode)
alebo na predvídanie správania zákazníkov. Toto všetko zohráva dôležitú úlohu v konkurenčnom
boji.
Obrovské množstvo údajov má ale slabú vypovedajúcu hodnotu bez bližšej analýzy.
Tu nastupujú metódy dolovania údajov, ktoré slúžia na nájdenie informácií v mase údajov. Ako sa uvádza v [2]:
Dolovanie údajov nie je tak jednoduchá metóda ako myšlienka, že v údajoch je viacej skrytých znalosti ako
je vidieť na povrchu. Z tohto pohľadu, do dolovania údajov patrí skutočne všetko "čo funguje".
Každá technika, ktorá pomôže získať viacej informácií z údajov je užitočná, a teda techniky
dolovania údajov sú značne heterogénna skupina.
Vzhľadom na už spomenuté, môžeme tvrdiť, že dolovanie údajov je multidisciplinárna oblasť, do ktorej
patrí učenie strojov, štatistika, databázové technológie, znalostné systémy a
predpovedanie údajov (pozri obr.č.1).

Modelovacie nástroje môžu byť rozdelené do dvoch skupín: vychádzajúcé z teórie a vychádzajúcé
z údajov [1]. Modelovanie vychádzajúce z teórie, často volané ako testovanie hypotéz, sa pokúsi dokázať
alebo vyvrátiť počiatočné nápady. Nástroje tohto modelovania potrebujú, aby bols používateľom špecifikovaná
väčšinu modelu založenom na predchádzajúcich znalostiach, a potom testovaná aby sme videli, či je model
správny.
Na druhej strane, nástroje pre modelovanie vychádzajúce z údajov automaticky vytvárajú model
založený na schémach nájdených v údajoch. Tento novonájdený model je tiež potrebné otestovať než ho
prehlásime za správny. Modelovanie je iteračný proces a konečný model je zvyčajne výsledkom kombinácie
predchádzajúcich znalostí a novoobjavených informácií. Takýto zdokonalený model často dáva
firme dôležitú konkurenčnú výhodu.
Medzi modelovanie vychádzajúce z teórie patria korelácie, t-testy, ANOVA lineárna a logistická regresia,
diskriminantná analýza, metódy predpovedania. Pozrieme sa na ich základné vlastnosti.
Korelácia je miera závislosti medzi dvoma premennými. Napríklad vysoká korelácia medzi nákupmi určitých
produktov ako syru a keksov prezrádza, že tieto produkty sa zvyknú spolu nakupovať.
Korelácie môžu byť buď pozitívne alebo negatívne. Pozitívna korelácia indikuje, že vysoká úroveň jednej
premennej bude sprevádzaná vysokou úrovňou korelačnej premennej. Negatívna korelácia indikuje, že vysoká úroveň
jednej premennej bude sprevádzaná nízkou úrovňou korelačnej premennej. Pozitívna korelácia je užitočná pre nájdenie
produktov, ktoré je možné predávať spolu.
Negatívna korelácia môže byť užitočná pre výmenu tovarov v obchodoch vo firemnej strategickej skladbe. Napríklad,
energetický podnik môže mať záujem o prírodný plyn a aj o palivový olej a od momentu keď sa zmenia ceny má stupeň zameniteľnosti
dopad na zvýšenie dopytu pre jeden zdroj pred druhým. Korelačná analýza môže pomôcť spoločnostiam vyvinúť portfólio
obchodov tak, aby stlmili takéto zmeny prostredia v jednotlivých obchodoch.
Ak chceme testovať či je rozdiel medzi konkrétnymi regiónmi, musíme použiť t-testy.
Na rozdiel od ANOVA, ktorá nám povie iba, či sú rozdielností vo viacerých regiónoch. Napríklad graf ANOVA nám povie, že
je rozdiel v servisných poplatkoch medzi kategóriami bicyklov. Avšak toto iba znamená, že kategória, ktorá má najvyššie
servisné poplatky je významne odlišná od kategórie, ktorá má najnižšie servisné poplatky. Ak chceme testovať, či dve stredné
kategórie majú rôzne servisné poplatky, použijeme t-test.
t-testy sú všeobecné testy na zistenie, či dve premenné majú rovnaké priemery, odchýlky alebo celkovú distribúciu.
Môžu byť tiež použité na testovanie, či priemery a odchýlky sa rovnajú špecifickej hodnote. Často sú používané v regresii, keď
sa testuje význam premennej. V tomto prípade testom je, či sa koeficient v regresii rovná nule.
ANOVA, ktorá predstavuje analytickú odchýlku, je štatistická technika, ktorá testuje odlišnosti v priemerných hodnotách
závislej premennej medzi dvoma alebo viacerými kategóriami nezávislých premenných. Napríklad ANOVA môže byť využitá pre testovanie, či je
rozdiel v príjmoch za predaje pre rôzne regióny.
Lineárna regresia je metóda, ktorá napasuje priamu čiaru skrz údaje. Ak je čiara naklonená do hora, znamená to, že nezávislá premenná
ako veľkosť kúpnej sily má pozitívny efekt na závislú premennú ako sú výnosy. Ak je naklonená do dola, je to negatívny efekt. Čím
strmší je sklon, tým väčší efekt má nezávisla premenná na závislu.
Logistická regresia odhaduje pravdepodobnosť určitej udalosti, ako je nastanie neplatenia pôžičiek.
Využiva spozorované faktory spojené s výskytom alebo absencoiu udalostí, aby modelovala pravdepodobnosť
výskytu vzhľadom na rôzne faktorové podmienky.
Diskriminantná analýza je klasifikáčna metóda, ktorá meria dôležitosť faktorov, určujúcich patričnosť do kategórie.
Napríklad môžeme chcieť testovať faktory vedúce k nevýmeňaniu CD. Ak sme schopný identifikovať správne faktory, náš model
by mal byť schopný využiť tieto faktory na rozlíšenie (diskriminovanie) medzi tými, ktoré sa vymieňajú a ktoré nie.
Predpovedanie je jedná z najpoužívanejších metód dolovania údajov. V predpovedaní si
používateľ zoberie údaje z minulosti pre danú premennú, ako sú predaje, a premietne premennú
do budúcnosti. Predpovedanie môže pomôcť s výberom vhodnej stratégie organizačného plánu
pre dlhodobý rast. Je tu veľké množstvo metód predpovedania zahrňujúc techniky regresie
časových sledov a neurónové siete. Mnoho týchto techník môžu získať nie len dlhodobe
lineárne trendy, ale tiež krátkodobé cyklické fluktuácie ako zobrazuje obrázok č.2.
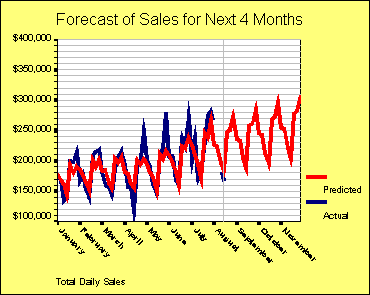
Obr.č.2 (prevzaté z [1])
Medzi modelovanie vychádzajúce z údajov patrí zhluková analýza, faktorová analýza, rozhodovacie stromy,
vizualizácia údajov, neurónové siete, asociačné pravidlá a pravidlová indukcia.
Zhluková analýza je technika redukcie údajov, ktorá zoskupuje buď premenné alebo prípady založené
na podobných charakteristikách. Táto technika je užitočná pre nájdenie zákazníckych segmentov založených
na spoločných charakteristikách ako sú demografické a finančné informácie alebo spôsoby nákupu.
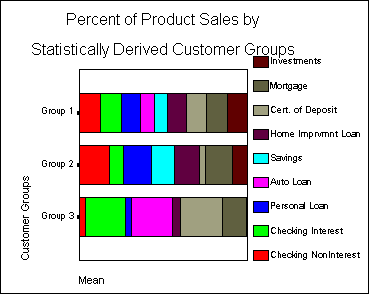
Obr.č.3 (prevzaté z [1])
Napríklad si predstavme, že banka chce nájsť segmenty zákazníkov, založených na typoch účtov, ktoré
si otvárajú. Zhluková analýza dala tri skupiny zákazníkov ako ukazuje diagram (viď obr.č.3). Rôznofarebné
pásy ukazujú percentuálnu veľkosť rôznych typov účtov otvorených zákazníkmi v rámci rôznych segmentov.
Prvý segment otvára rovnaký percentuálny počet všetkých produktov. Túto skupinu môžeme nazvať "všeobecní
zákazníci". Druhá segment otvára viacej hypoték, investičné kontá a domáce vylepšené pôžičky. Túto skupinu budeme
volať "dlhodobotermínoví zákazníci". A konečne tretí segment otvára viac termínované účty, sporové účty a osobné
pôžičky. Banka potom môže hľadať iné odlišnosti v chovaní, špeciálne prirodzený úbytok, medzi segmentmi
a môže potom zaobchádzať so segmentmi rôzne v závislosti na ich charakteristikách.
Analýza faktorov je ďalšou redukčnou technikou. Avšak na rozdiel od zhlukovej analýzy,
analýza faktorov vytvára model z údajov. Táto technika nájde podstatné faktory, tiež nazývané
"skryté premenné" a poskytne modely pre tieto faktory založené na premenných v údajoch.
Napríklad si predstavme, že máme výskum mapovania trhu, ktorý sa pýta na dôležitosť 9 atribútov
produktu. Predpokladajme tiež, že nájdeme tri podstatné faktory. Premenné, ktoré najviac zavážia
v týchto faktoroch, nám dajú niektoré potrebné informácie o tom, čo by tieto faktory mohly byť.
Napríklad, ak tri atribúty ako technická podpora, zákaznícky servis a dostupnosť tréningových
kurzov, všetky vedú hlavne do jedného faktoru, ktorý môžme nazvať "servis". Táto technika môže
byť veľmi užitočná v hľadaní dôležitých základných charakteristík, ktoré nemusia byť viditeľné, ale
ktoré môžu byť nájdené ako prejavy premenných, ktoré sme získali (viď obr.č.4).
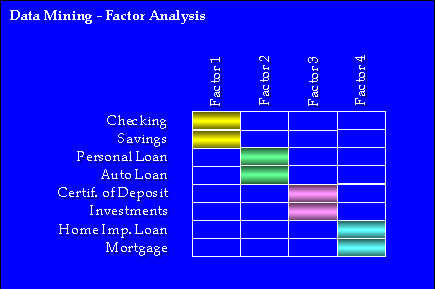
Obr.č.4 (prevzaté z [1])
Rozhodovacie stromy rozdeľujú údaje do skupín pravidiel, ktoré sú prijateľné, tak aby mali rôzny efekt
na cieľovú premennú. Napríklad, môžeme chcieť nájsť charakteristiky osôb, pre chod priamej pošty.
Tieto charakteristiky môžu byť preložené do pravidiel.
Predstavme si, že sme zodpovední za program priamej pošty navrhnutým pre predaj novej bankovej služby.
Aby sme maximalizovali zisk, chceme identifikovať domáci segment, ktorý podľa predošlých propagánd častejšie
odpovedá na podobnú propagandu. Zvyčajne sa to vykoná hľadaním kombinácií demografických premenných, ktoré najlepšie
rozlíšia tieto domácnosti, ktoré odpovedali na predošlú propagandu od tých, ktoré neodpovedali. Tento proces sa tiež
nazýva segmentácia údajov alebo segmentové modelovanie (bližšie informácie v [4]).
Tento proces dáva dôležité vodidlo, kto najlepšie zareaguje na novú propagandu a umožní nám maximalizovať našu
marketingovú efektívnosť posielaním správ iba tím ľuďom, ktorí častejšie zvyknú odpovedať, zvýšenie celkovej miery
odpovedajúcich a dúfajme, že aj zvýšenie predaja v tom istom čase.
Metódy rozhodovacích stromov obsahujú množstvo špecifických algoritmov, zahrňujúc klasifikáciu a regresiu stromov
(Classification and Regression Trees-CART), Chi-štvorcovú automatickú interakčnú detekciu (CHAID), C4.5 a C5.0 ako je
písané v [4].
Pozrime sa na príklad použitím CHAID algoritmu v strome odpovedí, aby sme zjednodušili segmentačný proces.
V diagrame na obr.č.4 môžeme vidieť, že 7% všetkých ľudí, ktorí prijali priamu poštu, odpovedali na ponuku. Avšak,
ak rozdelíme skupinu do tých čo vlastnia svoj dom oproti tým čo nie, môžeme vidieť, že 15% nájomníkov odpovedalo
zatiaľ čo iba 5% vlastníkov odpovedalo (viď obr.č.5). Môžeme pokračovať v rozdeľovaní skupín na segmenty aby sme našli segment, ktorý
má najväčšiu mieru úspešnosti. Tento segment môže byť vyjadrený ako pravidlo ako "ak príjemca je nájomník, a ak príjemca má
veľké rodinné príjmy, a konečne ak príjemca nemá úsporné konto, potom tento príjemca zvykne odpovedať s pravdepodobnosťou
45%". Alebo jednoduchšie, 45% segmentu s týmito charakteristikami zvykne odpovedať na priamu poštu.
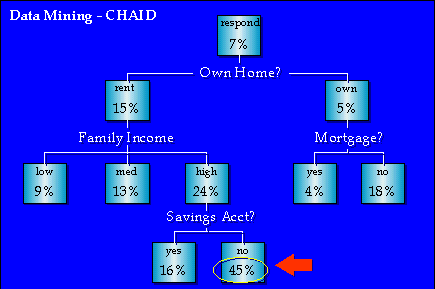
Obr.č.5 (prevzaté z [1])
CHAID algoritmus v strome odpovedí automatizuje proces nájdenia nášho najlepšieho cieľového trhu. Pomocou testov a štatistických
dôležitosti CHAID automaticky vytvára podskupiny údajov vo vzájomne sa vylúčujúcich a úplných segmentoch, ktoré sa významne líšia
v miere odpovedí na propagandu. Strom odpovedí potom zobrazí konečné segmenty v ľahko pochopiteľnom stromovom diagrame.
Vizualizačné nástroje využívajú prednosti ľudského vnímania ako metódu pre analyzovanie. To čo nemôžu čísla
ukázať, príslušný obrázok často môže. Napríklad, lineárny smer údajov nemusí byť evidentný z tabuľky údajov.
Avšak diagram, ktorý zobrazuje sled napojených bodov do rovnej čiary, zabezpečí okamžité preniknutie do údajových relácií
(viď obr.č.6).
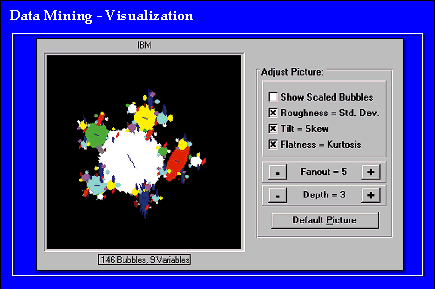
Obr.č.6 (prevzaté z [1])
S veľkou silou počítačovej grafiky môžu byť vizualizačnými nástrojmi tiež efektívne prezentačné nástroje.
Po vykonaní objavu ho musí analytik previesť do ľahko prístupného jazyka ako sú obrázky.
Neurónové siete sú údajové modely, ktoré simulujú štruktúru ľudského mozgu. Ako aj mozog, neurónové siete
sa učia z množiny vstupov a dolaďujú svoje parametre modelu vzhľadom na tieto nové znalostí, aby našli
schémy v údajoch.
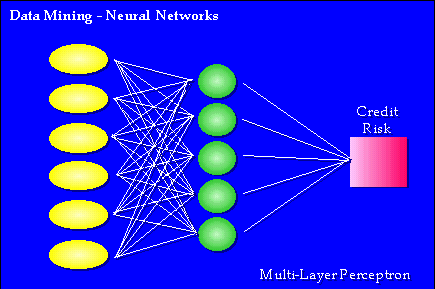
Obr.č.7 (prevzaté z [1])
Neurónové siete sú nelineárne svojim dizajnom, ale nepotrebujú explicitne špecifikovať funkcionálny tvar
ako to potrebuje nelineárna regresia. Výhodou je, že nie je potrebné mať na mysli nejaký špeciálny model, keď
sa spúšťa analýza. Neurónové siete môžu tiež nájsť interakčné efekty (ako sú efekty z kombinácie veku a pohlavia),
ktoré musia byť explicitne vyjadrené v regresii. Nevýhodou je ťažšia interpretácia výsledného modelu s jeho váhovými
vrstvami a tajomnými transformáciami. Neurónové siete sú preto užitočné pre predpovedanie cieľovej premennej, keď sú údaje
značne nelineárne, ale nie sú veľmi užitočné, keď tieto vzťahy údajov je potrebné vysvetliť.
Asociačné modely sú modely, ktoré vyšetrujú rozsah, s ktorými hodnotami jednej oblasti závisia hodnoty
druhej oblasti. Asociačné objavovanie hľadá pravidlá o prvkoch, ktoré patria k sebe
v nejakom prípade, ako sú nákupné transakcie. Pravidlá majú používateľsky stanovenú podporu, istotu a dĺžku
Pravidlá nachádzajú veci, ktoré "patria k sebe", čo je iné ako keď sú predpovedané. Tieto modely sú často
označované ako Market Basket analýza, ak sú aplikované v obchodnom priemysle, aby študovali nákupné schémy
ich zákazníkov.
Pravidlová indukcia je jedným z najbežnejších tvarov objavovania vedomostí. Je to technika pre objavovanie
skupín "Ak/Potom" pravidiel z údajov pre klasifikovanie rôznych prípadov. Pretože hľadá dôležité schémy v skupinách
údajov, je táto technika výkonná. Ale môže sa preplniť veľkým počtom pravidiel, ktoré je možné generovať.
Pretože sú pravidlá nezávislé, často si môžu navzájom odporovať a nemusia pokrývať všetky možné situácie.
Zväčša informácie s ohľadom na presnosť a pokrytie pre každý prípad poskytujú vodidlá ako je každé
pravidlo dôležité.
Techniky dolovania údajov vstupujú vo vyspelých krajinách bežne do obchodnej praxe. Na trhu sa nachádza niekoľko
desiatok produktov, ktoré majú implementované rôzne techniky dolovania údajov.
Najznámejší a najkvalitnejší produkt je SAS Enterprise Miner. Tento produkt je výnimočný v oblastiach ako sú
integrácia s aplikáciami, administrácia a sledovanie, prostredie, správa údajov, vysvetľovacie a predikatívne modelovanie.
SAS Institute má viac ako dvadsať ročnú tradíciu vo vyvíjaní softvéru na dodávanie informácií. Enterprise Miner
vznikol integráciou rôznych modulov SAS Systemu. Niektoré moduly zhromažďujú a vyhľadávajú údaje a iné aplikujú
štatistické modely a ďalšie zobrazujú výsledky. Enterprise Miner umožňuje používateľom bez hlbokých teoretických
znalostí vytvárať v grafickom prostredí predikatívne modely (regresia, neurónové siete a rozhodovacie stromy),
zhlukové analýzy, asociacie a aj sekvencie. Riešenie obsahuje aj metodológiu SAS Institute SEMMA (Sample-vzorkovanie,
Explore-skúmanie, Modify-modifikovanie, Model-modelovanie a Assess-vyhodnocovanie).
SGI Mineset od Silicon Graphics sa vyznačuje silnými vizualizačnými nástrojmi pre komplexné údajové sady.
Ponúka pokročilú 4D vizalizáciu - 3D grafy sa môžu meniť podľa dvoch ďalších premenných dimenzií. Jedná sa o proprietarné
riešenie pôvodne bežiace iba v prostredí SGI Irix, výsledky môžu byť zobrazované pomocou webového prehliadača. Má menšie
množstvo modelov pre dolovanie údajov. Je robený pomocou API plug-in architektúry, ktorá umožňuje portáciu iných nástrojov
do Minesetu. Sú tu implementované analytické metódy ako zhluková analýza, regresné a rozhodovacie stromy, rozhodovacie
tabuľky a analýzy evidencie.
Intelligent Miner od IBM je vyvážený produkt poskytujúci rôzne techniky, ktoré sú integrované do jedného modelu.
Používateľ je navigovaný pomocou wizardov, nastavenie parametrov je jednoduché. Ponúka najlepší clustering. Beží v prostrediach
AIX, MVS, OS/400, klient pod AIX, OS a Windows NT/95.
Existuje ešte mnoho ďalších produktov na dolovanie údajov. Ucelený zoznam aj s linkami môžete nájsť na
http://www.dbmsmag.com/. Nachádza sa tam niekoľko desiatok produktov.
CRISP-DM (CRoss-Industry Standard Process for Data Mining) je komplexná metodológia dolovania údajov a
procesný model vytvorený pre začiatočníkov aj expertov konzorciom priemyselných expertov. CRISP-DM model ponúka
"krok za krokom" návod, úlohy a ciele pre každé štádium procesu, zahrňujúc chápanie podnikania, chápanie údajov,
prípravu údajov, modelovanie, vyhodnotenie a ukladanie (viď obr.č.8). CRISP-DM model robí veľké projekty dolovanie údajov
rýchlejšími, viac efektívnymi a menej nákladnými umožnením používateľom, aby využili výhody už prevereného procesu.
Tento model pomáha ľuďom vyhnúť sa bežným omylom. CRISP-DM poskytuje:
odhad podnikateľských problémov a presvedčivé metódy na ich riešenie
získavanie a pochopenie údajov
identifikovanie a riešenie problémov v údajoch
aplikovanie techník dolovania údajov
interpretovanie výsledkov dolovania údajov v rámci podnikateľského kontextu
ukladanie a údržbu výsledkov dolovania údajov
získavanie a transformovanie expertíz, aby ďalšie projekty mali prospech zo skúsenosti
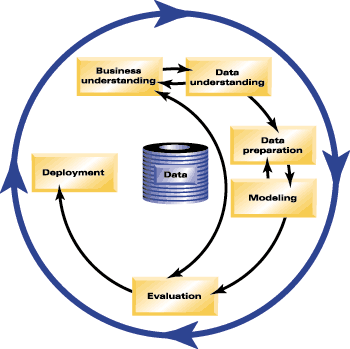
Obr.č.8 - Sumarizácia CRISP-DM procesov (prevzaté z [1])
CRISP-DM začal ako projekt založený v júli 1997 Európskou komisiou pre definovanie štandardných procesných modelov
pre vedenie projektov dolovania údajov. Prvá verzia metodológie bola dokončená v júne 1999.
Ďalšie informácie o projekte CRISP-DM ako aj popis tejto metodológie môžete nájsť na oficiálnych stránkach
http://www.crisp-dm.org/.
Dolovanie údajov je multidisciplinárna oblasť, ktorá obsahuje veľké množstvo rôznorodých techník. V posledných
rokoch zaznamenala rýchly rozvoj, čo bolo vyžiadané spracovávaním a analyzovaním ohromných množstiev údajov. Načrtli sme
rozdelenie techník dolovania údajov a detailnejšie sme popísali modelovanie vychádzajúce z údajov. Taktiež sme si popísali
najznámejšie aplikácie a novovzniknutú metodológiu CRIPS-DM. Dolovanie údajov bude čoraz viacej späté s umelou inteligenciou
a jeho techniky budú čoraz jednoduchšie pre používateľov. Žiaľ ekonomická situácia na Slovensku spôsobuje, že výdobytky
dolovania údajov využívajú iba najväčšie spoločnosti ako sú napr. mobilní operátory.
Trend ale jasne naznačuje, že dolovanie údajov bude pre firmy vecou prežitia v konkurenčnom boji.
Vypracované podľa:
[1] SPSS Inc.: Data mining techniques. http://www.spss.com/datamine/techniques.htm. 2000.
[2] Adriaans, P., Zantinge, D.: Data mining. syllogic, Addison-Wesley.
[3] Maršík, R.:Dolovaní dat-nastupující technologie na poli IT. CW 46/98, strana 4-6, IDG Czech, 1998.
[4] Brand, E., Gerritsen, R.: Data Mining Solutions. http://www.dbmsmag.com/. 1998.
Ďalšia literatúra:
Thraisingham, B.: A Primer for Understanding and Applying Data Mining. IT Professional 1-2/2000, strana 28-31, IEEE Computer Society. 2000.
Gerritsen, R.: Assessing Loan Risks: A Data Mining Case Study. IT Professional 11-12/1999, strana 16-21, IEEE Computer Society. 1999.
Khoshgoftaar, T., M., Allen, E., B.: Data Mining for Predictors of Software Quality. Internation Journal of SE and KE, World Scientific Publishing Company. 1999.
Katedra informatiky a výpočtovej techniky,
Fakulta elektrotechniky a informatiky,
Slovenská technická univerzita, Bratislava
(c) Pavol Boďo, 4.11.2000