Spracované podľa: Koziak Igor, Návrat Pavol: ANALYZER's Approach to Knowledge Representation for Automated Program Recognition. Knowledge-Based Software Engineering, Návrat and Ueno (Eds.), IOS Press, 1998, s.140-148
Abstrakt.Rozpoznávanie programov je založené na rozpoznávaní štandardných častí programov. Pomáha programátorovi porozumieť celkovej štruktúre programu a jeho funkcii. Je možné ho použiť na porozumenie programom, ktoré napísali študenti programovacích kurzov - zjednodušuje prácu pedagogickým pracovníkom pri kontrole a hodnotení zadaní. Tiež ho môžu využiť samotní študenti na kontrolu svojej práce. Pri rozpoznávaní programov je veľmi dôležitá reprezentácia znalostí. V tomto článku opíšeme reprezentáciu základných dátových štruktúr a základných konštrukcií, z ktorých sa jednotlivé programy skladajú. Výsledok rozpoznávania je postupnosť základných operácií, ktoré pracujú s dátovými štruktúrami a slovný popis programu.
Abstract (in English)
Automatické rozpoznávanie programov je veľmi náročná úloha. Pomáha pri znovupoužití zdrojových textov programov, pri hľadaní chýb, pri kontrole správnosti úloh študentov, pri rozširovaní funkčnosti podľa nových požiadaviek, atď. Problémom pri týchto úlohách je, že máme k dispozícii len zdrojové texty bez akejkoľvek dokumentácie. Pri rozsiahlejších programoch je ich pochopenie bez podpory automatického rozpoznávania časovo náročné. Prostriedky automatického rozpoznávania ponúkajú metódy a techniky na zjednodušenie tejto zdĺhavej a ťažkej práce.
Syntaktická analýza je nedostačujúca na pochopenie funkcie programu. Preto je treba použiť techniky automatického rozpoznávania programov, ktoré v zdrojovom kóde programu nájdu základné dátové štruktúry a základné algoritmy. Z týchto konštrukcií je vytvorený vývojový diagram. K nemu je pripojený popis jednotlivých častí, ktorý sa získa s bázy znalostí.
Výsledok rozpoznávania môžu využiť študenti programovacích kurzov na kontrolu svojich úloh a zadaní. Pre začiatočníkov je užitočné počas riešenia úlohy mať možnosť skontrolovať funkciu svojho programu. Automatické rozpoznávanie programov tiež môže pomôcť pri hľadaní sémantických chýb v programoch. Veľkú pomoc ponúka automatické rozpoznávanie programov aj učiteľom. Pri veľkom počte študentov a niekoľkých zadaní je výsledné množstvo programov veľké. Kontrola všetkých úloh bez použitia automatického rozpoznávania programov je časovo náročná a výsledky sú k dispozícii po neúmerne dlhom čase.
Rozpoznávanie programov je náročné pre veľké množstvo odchýlok v zdrojových textoch. Vyjadrenie tej istej operácie je možné veľa spôsobmi. Tu opíšeme príčiny, ktoré najviac ovplyvňujú veľké množstvo variácií zdrojových textov programov ([2]):
Identifikácia znalostí potrebných na rozpoznávanie programov je náročná úloha. Znalosti musia obsiahnuť veľké množstvo všeobecných algoritmov a ich obmeny. Našim cieľom je operácie vhodne zakódovať do bázy znalostí, aby bolo možné ich v programe rozpoznať.
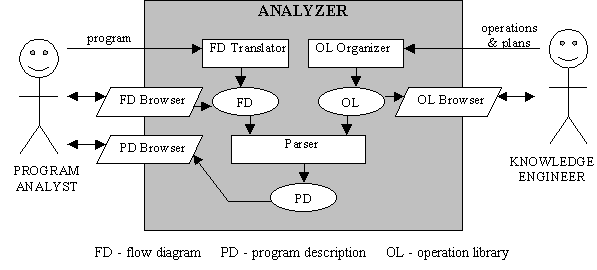
Architektúra programu je na obr.1. Externé entity systému sú znalostný inžinier a programový analytik. Vstupom je zdrojový text programu, ktorý do systému dodá programový analytik. Ten je systémom preložený na vývojový diagram, ktorý opisuje štruktúru programu a jeho hierarchické členenie. Tento vývojový diagram si môže analytik prezerať priamo v programe.
Aby bolo možné opísať vývojový diagram a teda aj funkciu programu, musia byť do systému dodané znalosti. Tieto znalosti, ktoré reprezentujú základné operácie a operácie na vyššom stupni abstrakcie - plány, do systému zadáva znalostný inžinier. Operácie a plány v knižnici operácií si môže znalostný inžinier prezerať pomocou OL Browsera. Operácie dodané do systému sú OL Organizérom spracované pre použitie Parserom. Parser z vývojového diagramu a operácií a plánov z knižnice operácií vytvorí hierarchický popis programu. Programový analytik si tento popis programu môže prezerať pomocou PD Browsera, ktorý je tiež súčasťou systému.
Obr. 1 Architektúra systému, podľa [1]
Požiadavky na systém môžeme rozdeliť do dvoch skupín. Prvá skupina predstavuje požiadavky zo strany programového analytika, druhá obsahuje požiadavky znalostného inžiniera.
Požiadavky programového analytika:
Znalosti reprezentujú dobre známe algoritmy a ich prácu s dátami. Pre zjednodušenie knižnice operácií a plánov (operation library, OL) sú všetky uzly (nodes) pracujúce s premennými nahradené priamym tokom dát zo zdroja do cieľa. Toho dôsledkom je, že tok riadenia (control flow) stráca veľkú časť významu. Znalosti teda budú obsahovať iba tok dát (data flow) ([1]). Je to na úkor špeciálnych prípadov, kde poradie vykonávania nezávislých výpočtov nad spoločnými dátami nie je bezvýznamné. V knižnici operácií sa môžu nachádzať aj rekurzívne funkcie.
Odhliadnuc od mnohých faktorov ovplyvňujúcich tieto požiadavky (hardvér, efektívnosť parsera, užívateľské rozhranie...), je najdôležitejšia reprezentácia a organizácia znalostí v knižnici operácií.
Na obr. 2 sú základné dátové štruktúry a operácie nad týmito dátami ([2]). Každý uzol na obrázku reprezentuje množinu operácií na nejakej spoločnej skupine dát (napr. FIFO) alebo základné iteračné funkcie (napr. Sum) alebo základné výpočtové operácie (napr. Increment). V každom uzle je zároveň uvedený názov konštrukcie, ktorú uzol reprezentuje. Šípky medzi uzlami reprezentujú vzťahy medzi objektmi. Smer šípky znamená, že zdrojový uzol je zovšeobecnením cieľového uzla alebo zdroj používa prvky z cieľového uzla. Napríklad šípka z uzlu Stack (zásobník) do uzlu Linked-list (lineárny zoznam) znamená, že operácie nad zásobníkom môžu byť implementované pomocou operácií lineárneho zoznamu.
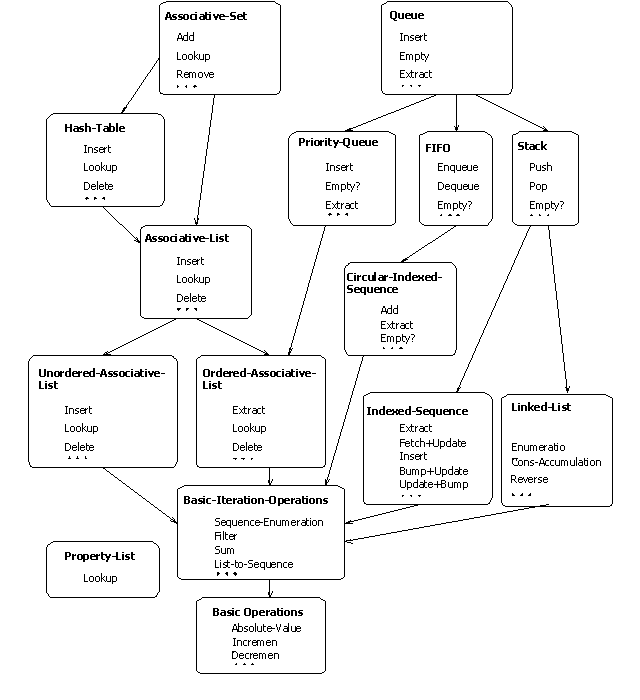
Obr. 2 Základné dátové štruktúry a operácie, podľa [2]
Aby bolo možné rozpoznať v zdrojov kóde použité algoritmy a dátové štruktúry, je potrebné mať v báze znalostí tieto algoritmy a štruktúry vhodne reprezentované. Báza znalostí obsahuje základné operácie a úlohy. Budeme ju preto nazývať knižnica operácií (OL - operation library). Obsahuje dva základné typy operácií: operácie a plány. Operácie delíme na základné operácie a úlohy. Operácia tu predstavuje výpočtovú konštrukciu, ktorá pre nejaký vektor vstupných parametrov vracia nejaký výsledok.
Plán predstavuje znalosť, ktorá hovorí, že operácia je implementovaná použitím nejakých iných operácií, špeciálne plán predstavuje priamo danú operáciu. Rozpoznanie tu potom znamená, že operácia o je implementovaná plánom p.
Plán je reprezentovaný grafom. Tento graf je orientovaný. Šípky predstavujú tok dát. Plán môže obsahovať tieto typy uzlov:
Uzly typu operácia, dáta a výstup sú prvky plánu. Všetky uzly typu operácia musia byť operácie z knižnice operácií.
Na obr. 3 je príklad operácie rm-dupls. Vstupom do operácie rm-dupls je zoznam prvkov. Výstupom z operácie je nový zoznam, ktorý neobsahuje duplicitné prvky. Uzol typu operácia označený "#" predstavuje volanie operácie, ktorú tento plán opisuje. Operácia označená "T-if-F" znamená, že ak má druhý argument hodnotu TRUE (pravda), je výstupom tejto operácie hodnota prvého argumentu, ak má hodnotu FALSE (nepravda), je výsledkom "T-if-F" hodnota tretieho argumentu.
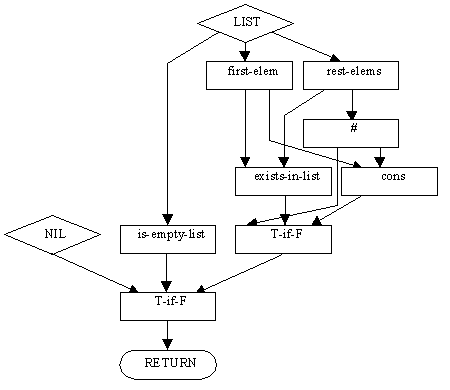
Obr. 3 Príklad reprezentácie operácií a plánov, podľa [1]
Na tomto príklade je vidieť ako možno použiť rekurziu v knižnici operácií.
Knižnica operácií obsahuje množinu základných operácií a množinu úloh. Každá úloha môže byť implementovaná pomocou niekoľkých nezávislých plánov.
Veľkosť množiny operácií a úloh je neúmerne veľká. Sú v nej zakódované úlohy, medzi ktorými sú len malé rozdiely. Napríklad rekurzívna funkcia, ktorá vráti zo vstupného poľa prvkov len tie prvky, ktoré sú väčšie ako tri. alebo napríklad rekurzívna funkcia, ktorá vráti zo vstupného poľa prvkov len tie, ktoré sú párne. Kostra týchto dvoch funkcií je rovnaká. Prechádza sa celý zoznam prvkov a vyberajú sa len tie, ktoré vyhovujú podmienke. Na ostatné prvky poľa je aplikovaná tá istá funkcia. Funkcií takéhoto typu je veľa. Je časovo aj priestorovo neúnosné všetky tieto kombinácie a možnosti vložiť do knižnice operácií. Zavedením šablón (schém) do bázy znalostí sa veľkosť bázy znalostí značne zmenší. A, samozrejme, bude knižnica operácií pokrývať omnoho väčšie množstvo úloh. Veľmi jednoduchým príkladom takejto šablóny je príklad ([3]):
(DEFUN <func> (X1...Xn)
(COND (<stop-test> <stop-hodnota>)
(<rekurzia-test> <rekurzivne-volanie>) ))
Podmienka <stop-test> predstavuje ukončovaciu podmienku rekurzie. Ak je splnená, funkcia vráti <stop-hodnotu>. Podmienka <rekurzia-test> určuje, kedy sa má vykonať rekurzívne volanie (zvyčajne TRUE). Pri rekurzívnom volaní sa volá funkcia <func> so zmenenými argumentmi. Množstvo úloh, ktoré táto jednoduchá schéma pokrýva, je veľké. Tu je vidieť mohutnosť techniky využívajúcej šablóny.
Okrem širokého pokrytia úloh nám šablóny ponúkajú veľké možnosti znovupoužitia knižnice operácií.
Pri návrhu šablóny je dôležité, aby jej prvky neboli presne špecifikované, ale aby tu bola nejaká voľnosť pre rôzne kombinácie konštrukcií. Šablóna je veľmi podobná plánu, avšak pribudol typ uzla rola. Tento uzol predstavuje operáciu, ktorá nie je priamo definovaná, ale je do šablóny doplnená podľa potreby. Rola tiež môže reprezentovať dáta. Šablóna sa využíva na definovanie plánov. Výsledkom rozpoznávania nemôže byť šablóna. Výsledok rozpoznávania môže byť napríklad: operácia o je implementovaná pomocou plánu p založeného na šablóne s.
Použitie tohoto formalizmu nám umožňuje definovať šablónu pomocou inej šablóny. Uzly predstavujúce rolu môžu (ale nemusia) byť nahradené časťami iných plánov, ktoré môžu obsahovať ďalšie role. Pri nahradení uzla rola v pláne p1 nejakým plánom p2, ktorý obsahuje role hovoríme, že plán p2 špecializuje plán p1. Týmto vzniká v knižnici operácií čiastočné usporiadanie použitím relácie "špecializuje" ([1]). Táto špecializácia zvyšuje možnosť znovupoužitia bázy znalostí.
Na obr. 4 je príklad definície šablóny. Šablóna predstavuje kostru pre určitú triedu úloh. Nahradením rolí inými plánmi alebo operáciami dostaneme veľké množstvo podobných úloh.
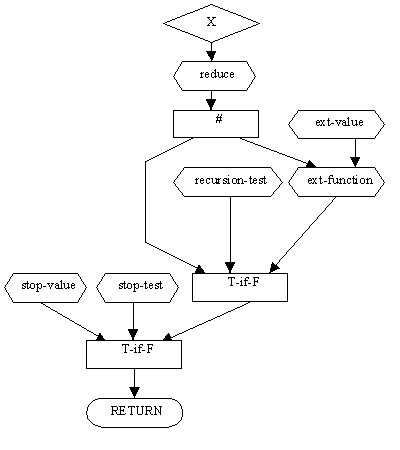
Obr. 4 Definícia šablóny, podľa [1]
Na obr. 5 je príklad, ako môžeme pomocou tejto šablóny zadefinovať operáciu rm-dupls z kapitoly č. 3. V obrázku je označené, ako sú jednotlivé role nahradené. Použitím šablón vnášame do knižnice operácií hierarchiu.
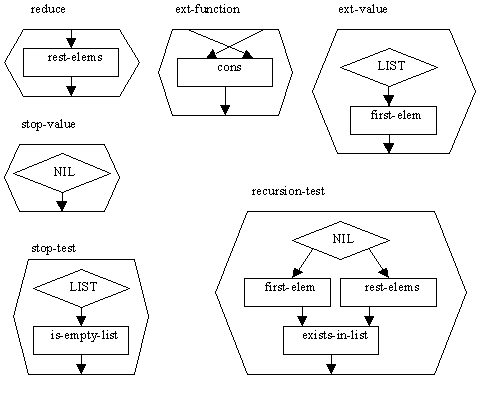
Obr. 5 Náhrada rolí v šablóne, podľa [1]
V tomto príspevku sme sa pokúsili načrtnúť problematiku automatického rozpoznávania programov a možnosti reprezentácie a organizácie znalostí v báze znalostí. Vhodná reprezentácia znalostí má zásadný vplyv na efektívnosť výsledného systému. Využitie šablón v báze znalostí veľmi zníži jej rozsah a zvýši pokrytie rozpoznateľných častí kódu. Využitie techniky šablón vnáša do systému robustnosť. Špecializácia plánov vytvára v knižnici operácií hierarchické usporiadanie, ktoré predstavuje prirodzenú organizáciu znalostí.
V tomto článku sme sa nezaoberali metódami návrhu plánov a šablón. Postup vytvorenia šablóny nie je jednoduchý. Môžu vzniknúť rôzne problémy (napr. šablóna nebude aplikovateľná v procese rozpoznávania alebo bude moc špecifická a pokryje len malé množstvo prípadov...) V budúcnosti je možné zamerať sa na formálnu špecifikáciu tvorby šablón a plánov. Je treba vypracovať teoretické podklady pre postupy, ktorými dostaneme čo najlepšie výsledky pre rôzne programovacie jazyky.
[2] WILLS Linda Mary: Automated Program Recognition by Graph Parsing, July 1992, MIT Doctoral Dissertation, http://users.ece.gatech.edu/~linda/phd-thesis.html, 25.10.2000
Znalostné systémy
Zimný semester 2000/2001