Inteligentné vyhľadávanie informácií
(Textové učenie a inteligentné
agenty)
Spracované podľa:Dunja Mledenic, J. Stefan Institute: Text-Learning and Related Intelligent Agents, IEEE Intelligent Systems & their applications, July/August 1999, pp: 44 - 54
Abstrakt:Cieľom tejto publikácie bol oboznámiť čitateľov problémami: hľadanie, filtrovanie a navigácia na Web-e a na Internete. Porovanli sme dve najviac používané prístupy - obsahovo-založený prístup a spolupracujúci prístup - pre rozvinutie inteligentných agentov. Pri prvom prístupe obsah (napríklad text) hrá dôležitú úlohu, pokiaľ pri druhom prístupe máme viacero znalostných zdrojov (napríklad viacero používateľov). Zameriame sa najmä na tri kritéria, ktoré sú nasledovné: akú reprezentáciu si treba zvolit pre textové dokumenty, aké množstvo slov treba uchovať a aký algoritmus učenia si treba zvoliť. Na konci ešte uvedieme konkrétne príklady inteligentných agentov, ktoré pomôžu nájsť požadovanú informáciu na Web-e, filtrujú elektronické noviny, a uvedieme konkrétnejšie agent Personal Web Watcher.
Kľúčové slová:inteligentný agent, inteligentné vyhľadávanie iformácií, obsahovo-založený prístup, spolupracujúci prístup
Abstract (in english)
V dnešnej dobe Internet sa využíva nielen vo výskumnej oblasti, ale poskytuje svoje služby aj pre širokú verejnosť. Cez Internet môžeme si získať obrovské množstvo informácií. Vzinkol tak nový pojem tzv. informačné zahltenie, ktoré znamená toľko, že dostaneme oveľa väcšie množstvo informácie ako v skutočnosti potrebujeme. Každý jedinec môže si pripojiť na celosvetovú pavučinu, môže si
vytvoriť svoju internetovú stránku a môže si dať tam rôzne informácie. Takto umožní aj ostatným používateľom, aby aj oni mohli získať tie vzácne dáta. Na internete môžeme nájst napríklad údaje o najnovších filmoch, informácie o rôznych konferenciách, môžeme tu prečítat aj najnovšie správy zo sveta a ešte dlho by sme mohli pokračovať. Bolo by to všetko perfektné, ale je tu jeden problém. Vzhľadom na to, že k Internete je pripojený veľa počítačov, jednotlivé informácie sa nenachádzajú iba na jednom stroji, ale sú distribuovane rozložené na viacerých počítačoch. Výsledkom je distribuovane prístupný zdroj informácií, ktorý obsahuje nehomogénne dáta. Nájsť potrebnú informáciu v takomto systéme zvyčajne nie je jednoduchou úlohou. Veľmi často nemáme na to ani potrebný čas aby sme našli ten pravý dokument, lebo používateľ potrebuje požadované údaje čo najrýchlejšie.Ako vieme uľahčit prácu používateľa, a nájst potrebné údaje? Tak, že používame elektronické pomocníky, tzv. inteligentné agenty alebo inteligentné používateľské rozhrania, ktoré pomôžu nájst dôležité informácie a tie informácie potom odporúčajú používateľovi. Pomocou takými systémami môžeme nájsť nie len textové súbory, ale aj hudbu, obrázky, videozáznamy a aj iné zaujímavé veci.
V tomto príspevku najprv v kapitole 2 uvedieme strojové učenie pre inteligentné agenty. Budeme to hovorit o používaných prístupoch pri vyhľadávanie informácií a uvedieme niekoľko existujúcich systémov. V kapitole 3 zase budme hovoriť o realizovanom systéme, ktorý má názov Personal Web Watcher, a ktrorý bol vyvynutý v J. Stefan Inštitúte. V kapitole 4 uvedieme základné poznatky o strojovom učení nad textovými údajmy. V kapitple 5 uvedieme záver a zhodnotenie. Na konci tejto príspevku sú uvedené aj jednotlivé zdrojové publikácie, z ktorých bol vytvorený tento príspevok.
V súčasnosti existuje niekoľkoľko rôznych definícií pre subjekt
inteligentný agent, my však budeme predovšetkým zaoberať s pomocnými systémami a odporúčajúcimi systémami, ktoré používajú strojové učenie alebo techniky dolovania údajov. Tie systémy pomôžu používateľovi nájsť požadované informácie alebo vykonajú jednoduché úlohy v záujme používateľa. Takýto systém môže byť napr. systém na vyhľadávanie podobných dokumentov na Internete, k už existujúcim dokumentom. Existujú dve najviac používané metódy, ktoré sa využívajú pri inteligentných agentoch:Obydbe prístupy dokážu nájsť a poskytnúť používateľovi potrebné informácie z celosvetovej pavučiny. V ďalších stranách uvedieme najvýznamnejšie systémy z oboch tried, pričom naznačíme súčasný trend.
Tento prístup robí textovú klasifikáciu tak, že vyhľadáva podobné dokumenty podľa obsahu, ktoré uprednostňuje používateľ. Podstata tejto prístupu je vo vyhľadávaní informácií. Samozrejeme tento prístup má aj určité nedostatky. Veľa z obsahovo-založených systémov zoberie do úvahy iba istý význam obsahov textových dokumentov, preto tie systémy potom majú nízky výkon. Okrem toho, obsahovo-založené systémy umožnujú aj vyhľadávanie dokumentov, ktoré sú podobné ako už nájdené dokumenty. Jednotlivé systémy obsahovo-založeného prístupu sú odlíšené podľa toho, akú metódu textového učenia využívajú. Tento prístup je veľmi populárny pri systémoch, ktoré pracujú s textovými údajmi, napr.: textové dokumenty na Internete alebo elektronické noviny. Teraz uvedieme niektoré existujúce systémy. V zátvorke uvedieme inštitúcie, kde boli vytvorené.
Web Watcher systém (CMU)
Tento systém pomôže používateľovi nájsť požadovné informácie na Web-e pomocou kľúcových slov, ktoré zadáva používateľ na začiatku hľadania. Systém potom ponúka odkazy a čaká zhodnotenie od používateľa. Celá činnosť tohto systému tak môžeme rozdeliť do tri časti. V prvej fáze systém čaká kľúčové slová od používateľa. V druhej fáze hľadá odkazy a prezentuje ich používateľovi. V poslednej fáze systém čaká ohodnoteni
e od používateľa, a tento znalosť potom systém využíva pri ďalšom hladaní.Lira (Stanford)
Tento systém sa naučí vyhľadávať informácie na Internete pre používateľa. Hľadá na Web-e tak, že sa zaujíma iba o ohraničené množstvo odkazov v určitom čase, vyberi najlepšie stránky a prijíma ohodnotenie od používateľa. Lira používa toto ohodnotenie na obnovu vyhľadávacej a vyberiacej heuristiky.
Musag (Hebrew Univ.)
Tento systém vyžaduje kľúčové slovo od používateľa a podľa toho hľadá na Internete požadované dokumenty. Počas práce generuje určitý druh slovníka alebo lexikonu, ktorý popisuje predstavu systému o používateľa. Toto je semanticky taká istá ako pri ostatných obsahovo-založených systémoch. Musag používa tento generovaný slovník pri vyhľadávaní dokumentov
a na rozšírenie množinu daných kľúčových slov, ktoré už pozná.Letizia (MIT)
Je to agent používateľského rozhrania, ktorý pomôže pri vyhľadávaní informácií na Web-e. Tento systém nevyžaduje žiadne kľúcové slová ani žiadne ohodnotenie od používateľa, lebo usudzuje používatelské záujmy počas hľadania na Internete. Používatelia počas hľadania zvyčajne uprednostňujú hľadanie do hĺbky. Pokiaľ používateľ prečíta aktuálny internetový dokument, Letizia vykoná hľadanie do šírky od aktuálného dokumentu. Systém zapam
ätá potencionálne zaujímavé odkazy nájdené počas hľadania a prezentuje ich používateľovi v samostatnom okne.Personal Web Watcher (CMU, IJS)
Je to osobný pomocník pri hľadaní na Web-e. Systém prevádza používateľa zo stránky na stránku, pričom si zapamätá používateľské záujmy, záľuby a jednotlivé odkazy. Systém na základe obsahovej analýze generuje záujmovú oblasť (profil) používateľa a robí to bez potreby kľúčových slov a bez ohodnotenia od používateľa.
CiteSeer (TX, NEC UMIACS)
Systém pomôže používateľovi nájsť požadované výskumné publikácie na celosvetovej pavučine pomocou zadania kľúčových slov a využitím hľadacieho mechanizmu na nájdenie požadovaných dokumentov (PostScript súbory na Web-e). Systém potom vytiahne záhlavie, abstarkt a citácie z publik
ácie. Systém tiež nájde podobné publikácie, založené na spoločných citáciach v publikáciach.FAQFinder (Chicago Univ.)
Tento systém používa prírodzený jazyk na komunikáciu s používateľom. Používateľ zadá otázku, na ktorú chce dostať odpoveď a systém snaží tento odpoveď získať z FAQ súborov. Systém podľa zadanej otázky vyberie päť otázok, ktoré najviac podobajú na zadanú otázku, tie systém prezentuje používateľovi spolu s príslušnými odpoveďmi.
Antagonomy (NEC)
Tento systém vytvorí osobné noviny na Web-e, sleduje používateľské akcie nad článkami a tie poznatky uchová. Noviny sú vytvorené podľa bodovania článkov, ktoré naznačuje používateľské záujmy - články, ktoré dostanú vyššie odnoteni dostanú sa na vyššiu pozíciu vo vytvorených novinách.
Oproti obsahovo-založeného prístupu využívajúcu textovú klasifikáciu, ktorú úspešne môžeme využívať pri jedného používateľa, spolupracujúci prístup predpokladá skupinu používateľov, ktorí spoločne využívajú možnosti celého systému. Pri tejto prístupe (niekedy nazvaný aj ako spoločenské učenie), oznámenie pre používateľa je závislé od reakcie ostatných používateľov. Systém hľadá takých používateľov, ktorí majú podobné záujmy. Spolupracujúci prístup namiesto podobnosti článko
v skúma podobnosť záujmov jednotlivých používateľov, pričom nie je analyzovaný obsah jednotlivých článkov. Každý prvok je jedinečne identifikovaný a má ohodnotenie od používateľa. Podobné hodnoty medzi používateľmi naznačujú, že používatelia majú podobný záujem. Ak do databázy je zaradený nový prvok, systém si musí zozbierať informácie od všetkých používateľov, aby vedel to prípadne používateľovi odporúčať. Je zrejmé, že keď niektorí používatelia majú nezvyčajnú záujmovú oblasť to nebude zhodovať s žiadnou inou, preto systémový výkon bude nízky. Takýto príklad je zobrazený na Obr.1. Jednotlivé čísla naznačujú ohodnotenie hudby od jednotlivých používateľov (1 – najmänej preferovaný, 7 – najviac preferovaný). Vidíme, že Používateľ-1 a Používateľ-2 majú skoro takú istú záujmovú oblasť, kým Používateľ-3 má celkom iný záujem.|
Hudba |
Chopin |
Bach |
Matheny |
Balasevic |
Prodigy |
Presley |
ABBA |
Enya |
|
Používateľ-1 |
6 |
7 |
5 |
7 |
1 |
2 |
3 |
7 |
|
Používateľ-2 |
7 |
6 |
6 |
7 |
1 |
1 |
5 |
6 |
|
Používateľ-3 |
2 |
1 |
1 |
1 |
7 |
6 |
6 |
3 |
Obr. 1: Príklad na spolupracujúci prístup (spracovaný podla
[1])Spolupracujúci prístup zvyčajne sa používa pre netextové údaje (napríklad video alebo hudba), ale existujú aj systémy, ktoré používajú tento prístup nad textovými informáciami (napríklad filtrovanie elektronických novín). Teraz podobne ako pri obsaovo-založenom prístupe, uvedieme niektoré existujúce systémy.
Firefly, Ringo (MIT)
Sú to inteligentné agenty požívateľského rozhrania, ktoré sa učia tak isto od používateľa ako aj od ostatných agentoch. Takýto agent vie manipulovať s elektronickou poštou, s naplánovanými schôdzkami a vie filtrovať elektronické noviny. Firefly je rozvynutý systém pre hľadanie hudby, videa ale odporúča aj knihy vyskytujúce
sa na celosvetovej pavučine. Firefly vyžaduje od používateľa, aby začal pracovať s niekoľkými preddefinovanými témami, aby systém vedeľ porovnať ľubovoľných dvoch používateľov (používatelia môžu byť porovnané, ak vyskytujú pri nich rovnaké prvky. Tento systém presnejšie je opísaný v [3] Ringo pokúsi prekonať problém riedkého ohodnotenia tak, že vytvorí modelov virtuálnych používateľov, ktorí majú veľmi úzky záujmovú oblasť.GroupLense (Minnesota)
Je to spolupracujúci systém na filtrovanie elektronických novín. Jeho databáza je rozdelená na dve časti. V prvej sú uchované používateľské ohodnotenia, v druhej sú vzájomné vzťahy medzi dvojicami používateľov. Preto, lebo každý používateľ prečíta iba malé percento z nových oznamov (bude ho zaujímať iba malé percento), potrebujeme obrovské množstvo čísel na ohodnotenie. Tento je veľký problém pri spolupracujúcom prístupe a jednotlivé systémy riešia to inak a inak. GroupLense rozdelí množinu nových oznamov do klusterov, ktoré môžu používatelia spoločne prečítať. Takto sa zlepší lokálna hustata ohodnotení.
Fab (Stanford)
Systém používa obsahovo-založený prístup na generovanie záujmovej oblati jedného používateľa, potom používa spolupracujúci prístup na hľadanie podobných používateľov. Používateľské ohodnotenie sú použité na aktualizáciu používateľských profilov. Fab skúma podobnosti medzi používateľmi pomocou podobnosti medzi ich záujmami.
WebCobra (James Cook Univ.)
Tento systém používa podobnú myšlienku na kombináciu obsahovo-založeného prístupu a spolupracujúceho prístupu. na textovú klasifikáciu. Systém generuje používateľské záujmové oblasti z požadovaných dokumentov. Systém spojí používateľov do spolupracujúce klustre,podľa ich podobnosti záujmu.
Lifestyle Finder
Aj tento systém kombinuje už spomenuté dve prístupy. Používa dotazník aby dostal charakteristiky používateľa a spojí používateľov so spoločnými záujmami. Lifestyle Finder navrhne množinu 15 najvyššie ohodnotených Web stránok od každého používateľa. Tie sa používajú na ohodnotenie výkonnosti.
Web je rýchlo pribúdajúci informačný zdroj, na ktorom v jednom čase veľa používateľov sa zaujíma o rôzne údaje. Preto, lebo interakcia s Internetom sa prebieha cez počítačov, môžeme používať počítače na pozorovanie a uchovanie používatelských akcií, aby systém mohol pomôcť pri navigácie na Internete. Textové učenie môže byť aplikované iba n
ad zozbieranými informáciami. Jeden takýto systém je Personal Web Watcher, ktorý bol vyvynutý na inštitúte J. Stefan. Tento systém je podrobnejšie opísaný v publikácie [3].Systém Personal Web Watcher môže používateľ lokálne nainštalovať a môže si pripojiť k celosvetovej pavučine ako proxy server. Tento systém je vlastne obsahovo-založený osobný agent, ktorý pomôže používateľovi vyhľadávať informácie na Internete. Používateľ počas hľadania používa vyhľadávacie nástroje na zís
kanie požadovaného dokumentu, a ďalej veľmi často klikne na odkazy, ktoré sú uvedené na nájdenej stránke. Predpoveď a zvýraznenie kliknutých odkazov je jeden z ciest pomôcť si používateľovi navigovat na Web-e. Pri strojovom učení, berieme všetky odkazy ukázané používatelovi ako trénovacie príklady s boolovskou hodnotou (kliknuté, nekliknuté). Medzi tím si vytvoríme popis odkazov a narábame s tími ako skrátenými dokumentami ako trénovacie príklady pre strojové učenie. Prvá verzia tohto systému používala množinu-slov na reprezntáciu dokumentov a používala prostú Bayesian klasifikáciu.
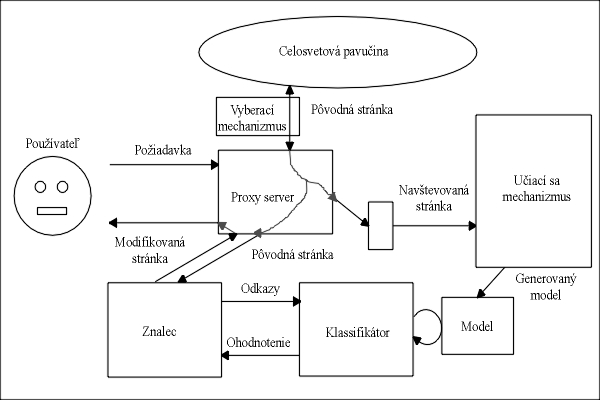
Obr. 2: Štruktúra systému Personal Web Watcher (spracovaný podľa
[1])Hlavnou myšlienkou bol, aby systém vedel pomáhať používateľovi bez potreby zadania kľúčových slov. Štruktúra systému je zobrazená na Obr. 2. Personal Web Watcher sa skladá z dvoch hlavných časti. Prvá časť je proxy server, ktorý komunikuje s používateľom. Druhá časť je učiaci sa mechanizmus, ktorý poskytuje používateľský model pre server. Komunikácia medzi nimi je pomocou lokálneho úložiska tak, že proxy server uchová adresu návštevovaných dokumentov (URL), a učiací sa mechanizmus používa tie na vyhľadávanie dokumentov a na generovanie modelu používatelského profilu.
Veľa súčasných inteligentných agentov, ktoré používajú techniky strojového učenia, používajú obsahovo-založený prístup a učia sa z obsahu textových dokumentov. Textové učenie je jedna aplikácia techniky strojového učenia nad textovými databázami. V tomto kapitole budeme sa snažiť odpovedať na nasledujúce tri otázky:
Reprezentácia: Najviac používaná reprezentácia je tzv. vektorová reprezentácia, ktorá slúži na reprezentáciu dokumentov pri vyhľadávaní informácií a pri textovom učení. Je to tzv. bag-of-world (množina-slov) reprezentácia. Hlavná myšlienka je v tom, že všetky slová z dokumentu sú spracované tak, že uchováva ich počet výskytov. Takýmto spôsobom každý dokument je reprezentovaný svojou vlastnou množinou slov, ktoré vyskytli v danom dokumente. Takýto príklad je naznačený na Obr. 3. Pri takomto prístupe môžu byť použité aj dodatočné informácie, napríklad: vetové štruktúry, poloha slov, susedné slová, atď. Otázkou je to, že čo môžeme získat, keď budeme uchovávať aj už spomenuté dodatočné informácie (a aké informácie zvážit) a aká je cena, ktorú musíme zaplatiť.
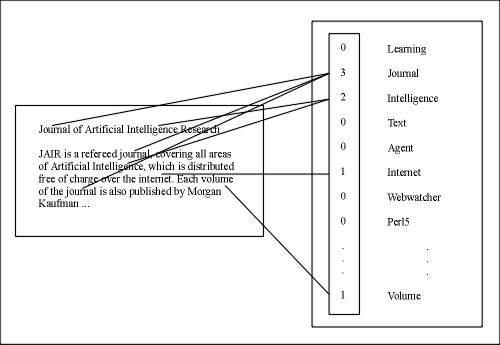
Obr. 3: Reprezentácia textových dokumentov pomocou množinou-slov (uvedený v
[5])Niektoré výskumy sa zaoberali možnosťami, čo sa stane, ak textový dokument nie je dostatočne dlhý. V takýchto prípadoch môžeme robyť taký istý prístup ako bol uvedený, rozdiel je iba v tom, že nebudeme pracovať so zvláštnými slovami, ale s dvojicami resp. n-ticami. Našu reprezentáciu teda môžeme rozšíriť na sekvenciu slov, a môžeme takto zlepšiť výkonnosť klasifikátora, ktorý pracuje s krátkymi dokumentami.
Počet slov: Najviac používaný prístup na redukovanie počet rôznych slov je taký, že odstránime slová, ktoré sa nachádzajú v tzv. “stop zozname”. Pre anglický jazyk sú to slová napríklad: “a,” “the,” alebo “with”. Druhý prístup je taký, že odstránime tie slová, ktoré sa vyskytujú veľmi zriedkavo (frekvencia slova < minimáln
a frekvencia). Pri jazykovo závyslých prístupoch môžeme redukovat slová i tak, že jednotlivé tvary slov nahradíme základným tvarom. Napríklad v anglickom jazyku slová works, working a worked nahradíme slovom work.Veľa metód používa aj jazykovo nezávislé prístupy. Pri tých prístupoch oddelíme tie slová, ktoré sú najsľubnejšie tak, že používame na redukovanie všetkých slov hodnotu LSI (Latent Semantic Indexing).Algoritmy: Pri vyhľadávaní údajov najpoužívanejšia technika je taká, že používame množinu-slov pre každý dokument zvlášť. Vtedy sa využíva tzv. TFIDF-vektor. Pre každú zložku dokumentového vektora platí:
d(i) = TF(wi, d)IDF(wi),
pričom TF je frekvencia termov (term frequency), ktorá označuje koľkokrát sa vyskytol daný term w
i v dokumente a IDF=log[D/DF(wi)] je inverzná dokumentová frekvencia (inverse document frequency), kde D je počet dokumentov, a DF(wi) je počet dokumentov, kde term wi sa vyskytol aspoň raz. Prístup potom reprezentuje nový dokument ako vektor. Existujú aj ďalšie algoritmy, ktoré sú uvedené v publikáciach [4] a [1] , my však stými nebudeme zaoberať.Tento príspevok bol spracovaný podľa uvedených publikáciach na predmet Znalostné systémy. Chceli sme uvádzať čitateľov do problematiky vyhľadávanie údajov na Internete. Snažili sme naznačiť súčasnú problematiku - informačné zahltenie, a systémy, ktoré môžu pomôcť používateľovi získať si požadované dokumenty, hudbu, videzáznamy,
atď. Oboznámili sme čitateľov existujúcimi systémamy a ich základnými funkciami. Nakoniec si cheme zdôrazniť, že výskum podobných systémov je aj naďalej veľmi dôležité a dúfame, že vzniknú ešte lepšie systémy ktoré budeme my používatelia plne využívať.[1] Dunja Mladenic, J. Stefan Institute: Text-Learning and Related Intelligent Agents: A Survery, IEEE Intelligent Systems & their applications, July/August 1999, pp: 44 - 54
[2] Dunja Mladenic: Personal Web Watcher: Implementation and Design, Tech. Reprt IJS-DP-7472, http://www-ai.ijs.si/DunjaMladenic/papers/PWW/pwwTR.ps, 1996, Last update: March 2000, Last access: 3. November 2000
[3] Sara Hedberg: Agents dor sale: first wave of intelligent agents go commercial, IEEE Inteligent Systems & their applications, November/December 1996, pp: 16 - 19
[4] Tom Mitchell: Experience with a Learning Personal Assistant, http://www.cs.cmu.edu/afs/cs.cmu.edu/prokect/theo-20/www/mitchell-pubs/cacm94.ps, 1994, Last update: unknown, Last access: 3. November 2000
[5] Dunja Mladenic: Machine Learning on Nonhomogeneus, Distributed text data, http://www-ai.ijs.si/DunjaMladenic/papers/PhD/PhDFinal.ps, 1998, Last update: March 2000, Last access: 3. November 2000
Znalostné systémy
Zimný semester 2000/2001