Spracované podľa: UENO, Haruki: A Generalized Knowledge-Base Approach to Comprehend Pascal and C Programs, In: P. Návrat, H. Ueno: Knowledge-Based Software Engineering, IOS Press, 1998, s. 132-139
Abstrakt. Systémy na pochopenie programov (resp. na kontrolu správnosti programov) možno využiť na podporu učenia programovacích techník začiatočníkom. Analyzovaním programu používateľa, systém dokáže odhaliť a usudzovať chyby a dáva návody nielen na opravu chýb, ale aj objasní nepochopenia daného algoritmu. Systémy ALPUS (ALPUS II) a DISCOVER boli vyvinuté práve na tie účely. Kým ALPUS využíva vlastnosti produkčného systému na pochopenie programov, DISCOVER používa implicitne dané znalosti. Znalosti v systéme ALPUS sú reprezentované pomocou hierarchického grafu nazvanom HPG (Hierarchical Procedure Graph). DISCOVER používa techniku sledovania modelu (model tracing) pomocou cieľov a plánov. Z toho vyplývajú základné rozdiely medzi nimi, ich výhody a nevýhody.
S problematikou porozumenia programov sa zaoberajú na celom svete. Tieto systémy nahradzujú ľudského učiteľa, ktorý pomáha študentovi v písaní programov, odhalenia a usudzovania chýb a dáva návody nielen na opravu chýb, ale aj objasní nepochopenia daného algoritmu. Avšak kým učiteľ pozoruje zdrojový program na obrazovke počítača, tým tieto systémy to robia z vnútra počítača. Určenie správnosti programov možno využívať vo výučbe najmä na:
Na riešenie problému je vhodné používať znalostné systémy. Boli vyvinuté
systémy na porozumenie programov s používaním znalostných systémov, ako je ALPUS [3], ALPUS II [2]. ALPUS a ALPUS II sú subsystémami
inteligentného prostredia INTELLITUTOR [2, 3], ktorý slúži na
výuku programovania a je implementovaný v rámcovom znalostnom prostriedku ZERO.
DISCOVER [1] používa implicitné znalosti na kontrolu programov,
preto je vhodný na porovnanie systémov s bázou znalostí. Tento model používa metódu
sledovania modelu (model tracing). Tento prístup používajú systémy PROUST [1], Lisp Tutor [1], a GIL [1].
V článku nasleduje charakteristika týchto systémov, výsledky testovania a vzájomné
porovnanie jednotlivých systémov.
Pochopenie programu je podobný ako pochopenie prirodzeného jazyka, nakoľko sú
založené na spracovaní viet. Samozrejme medzi nimi je veľký rozdiel, lebo kým
prirodzený jazyk nie je jednoznačný, programovacie jazyky popisujú presný postup
spracovania údajov.
V [3] sú uvedené základné typy pochopenia programov :
Tieto systémy padajú do prvej skupiny, t.j. sú schopné porozumieť program (časť programu) na základe svojich znalostí. Kroky pri analýze programov sú prevzaté zo života, ako učiteľ analyzuje program študenta a snaží sa nájsť chyby v postupe:
Tieto 3 kroky sú základom pri pochopení programov, čo aj potvrdí definícia programu:
program = údaje + algoritmus.
Tento spôsob počítačového pochopenia programov je používaný v systémoch ALPUS
a ALPUS II.
Systémy DISCOVER, PROUST, Lisp Tutor, GIL sú založené na inom princípe - sledovanie
modelu. Tieto systémy vychádzajú z cieľa programu, t.j. z špecifikácie problému.
Aplikácia dáva zadanie používateľovi, ktorý napíše program. Po každom kroku (po
každom napísanom riadku) systém kontroluje, či programátor je na správnej alebo na
chybnej stope. Pri detekcií chybného kroku sú chyby ihneď oznamované. Vtedy
programátor má možnosť (a zároveň aj musí) opraviť chybu.
ALPUS a ALPUS II používa tzv. HPG graf (Hierarchical Procedural Graph) na opis
algoritmu. V formalizme procesy sú znázornené s obdĺžníkmi a postupnosť procesov je
značená šípkami. Hrubé obdĺžníky predstavujú procesy, ktoré majú funkciu -
popisujú časť operácie. Jednoduché obdĺžníky popisujú agregáciu procesov, čiže
zahŕňa väčšiu časť operácií (všeobecnejšie). Tieto procesy sú len formálne,
nemajú žiadnu funkciu. Opakovacie procesy sú reprezentované dvojitými obdĺžníkmi.
Ako príklad v [2, 3] zvolili algoritmus Quicksort, ktorého úlohou
je triedenie postupnosti údajov. Tento algoritmus je známy a nie je ani jednoduchý, ani
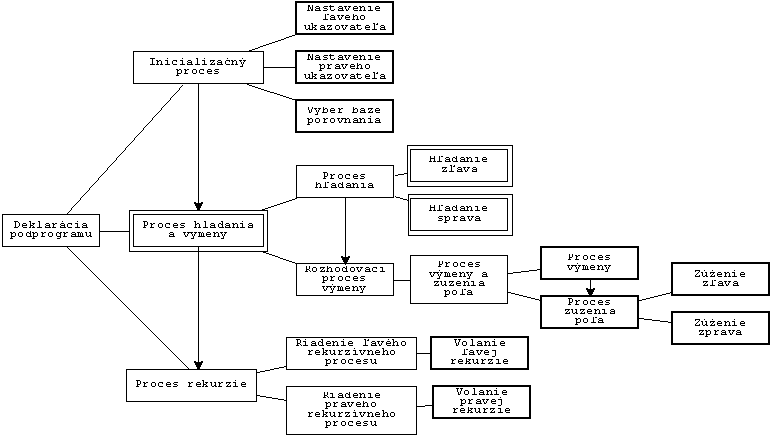
veľmi zložitý. Na obrázku č.1 je znázornený HPG graf algoritmu
Quicksort, ktorý sa skladá z troch hlavných procesov:
Tieto hlavné procesy sa skladajú z ďalších častí. Inicializačný proces zahrňuje 3 paralelné procesy: Nastavenie ľavého ukazovateľa, Nastavenie pravého ukazovateľa a Výber báze porovnania. Na poradí vykonávania týchto procesov nezáleží, preto im hovoríme, že sú paralelné. Proces hľadania a výmeny je opakujúci proces, ktorý obsahuje 2 subprocesy: Proces hľadania a Rozhodovací proces výmeny. Proces hľadania zahŕňa procesy Hľadanie zľava a Hľadanie sprava, ktoré sú opäť paralelné. Úlohou týchto procesov je nájsť menší (väčší) prvok ako bázový prvok. Rozhodovací proces potom rozhoduje o výmene týchto znakov a obsahuje procesy na výmenu (výmena sa uskutočňuje iba vtedy, ak index neprešiel cez bázový prvok). A nakoniec Proces rekurzie znázorňuje rekurzívne volanie na 2 vzniknuté postupnosti.
Obr. 1.: HPG graf pre algoritmus Quicksort (podľa [2, 3])
Funkcia každého procesu v HPG grafe je popísaná sémantickou sieťou (obr.
2.). Kvôli zovšeobecneniu sa používajú všeobecné premenné. Opakovanie procesu
Proces hľadania a výmeny znázorňuje REPEAT - WHILE cyklus, pričom podmienkou na
ukončenie je výraz V3>V4, t.j. ak ľavý index je väčší ako pravý, cyklus sa
zastaví. Telo cyklu pozostáva z dvoch procesov, ako je to aj na HPG grafe. Hľadanie
zľava (resp. sprava) opäť obsahuje cyklus, ktorý nájde väčší (resp. menší)
prvok ako báza. Potom tieto prvky sú vymenené v procese Proces výmeny (samozrejme ak
je to potrebné). V báze znalostí k jedným procesom možno priradiť viaceré spôsoby
implementácie. Čím viac znalostí obsahuje báza znalostí, tým lepšie vie aplikácia
rozpoznať a pochopiť program.
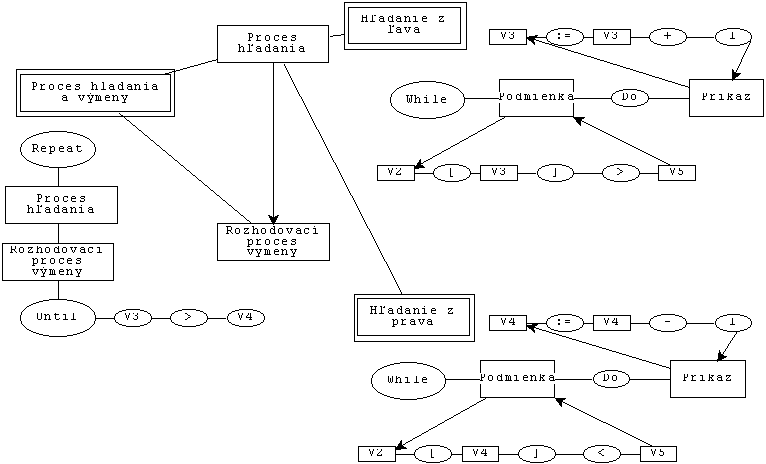
Obr 2. Priradenie funkcií k procesom (podľa [2, 3])
V2-pole, V3-ľavý ukazovateľ, V4-pravý ukazovateľ, V5-hodnota bázového prvku
ALPUS II sa skladá z 4 hlavných krokov procesu pochopenia programov (obr.
3.):
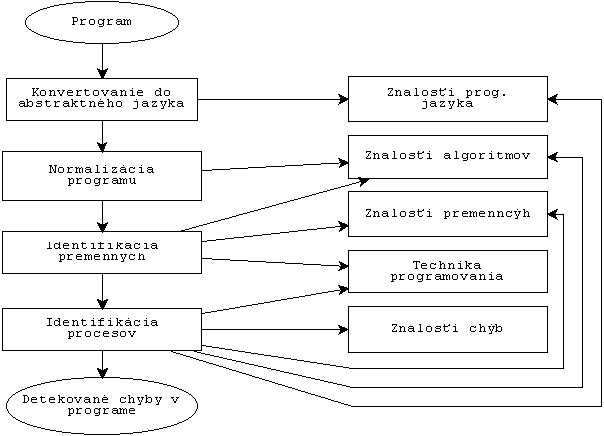
Obr. 3.: Architektúra systému (podľa [2])
Takisto ALPUS obsahuje tie základné procesy, s rozdielom, že prvý krok je zahrnutý do
normalizácie programu. Stručný popis jednotlivých krokov (podľa [2]):
Program v jazyku C alebo Pascal je konvertovaný do abstraktného jazyka AL (abstract language). Dôsledkom toho je, že ďalšie kroky sú jazykovo nezávislé. Tým sa zjednodušuje báza znalostí, lebo obsahuje len znalosti pre jazyk AL. Jazyk AL je podobný jazyku Lisp, t.j. používa prefixové operácie.
Cieľom normalizácie je dosiahnutie väčšej flexibility v pochopení programov. Normalizácia zahrňuje zjednodušenie výrazov, štruktúry programu, zrušenie deklarácií konštánt a zložených záznamov.
Identifikácia úloh premenných je na základe znalostí o premenných. Tento krok je veľmi dôležitý, nakoľko študentské programy a "vzorové" programy v báze znalostí používajú iné premenné. Keby každý program bol správny, potom tento krok by bol veľmi jednoduchý, lebo vtedy viem každú premennú jednoznačne identifikovať. Ale čo s chybným programom, v ktorom premenné sú vymenené - napr. chybné používanie ukazovateľov. Vtedy identifikácia nie je jednoznačná. Preto pri analýze identifikátorov je program rozdelený na segmenty podľa HPG grafu. Úloha identifikátora sa potom určuje podľa toho, aby bol čo v najväčšom počte segmentov správny. Táto metóda pracuje dobre aj vtedy, keď skúmaný program obsahuje aj chyby alebo je neúplný.
Posledným krokom je detailná identifikácia procesov. Je založená na porovnávaní vzorov a aplikuje sa na každý uzol v HPG grafe. Báza znalostí obsahuje viac vzorov (obr. 4), ktoré možno zaradiť do 3 skupín (podľa [3]):
Najprv každý segment programu je porovnávaný so štandartným vzorom. Keď porovnávanie je neúspešné, potom systém porovnáva segment s prijateľnými vzormi. Pri zhode dostaneme varovanie, že to nie je najlepší výber príkazu. Inak sa v porovnávaní pokračuje s chybnými vzormi. Keď ani medzi chybnými nenájde identický vzor, potom segment je považovaný ako chybný. Výhodou používania chybných vzorov je, že vopred čakané chyby systém identifikuje a dá návod na ich opravu.

Obr 4.: Metóda pochopenia programov rozpoznávaním vzorov (podľa [3])
Na znázornenie celého procesu uvádzam príklad na výmenu dvoch prvkov poľa (Proces
výmeny):
pole[left]:=pole[right];
pole[right]:=pole[left];
Na prvý pohľad vidíme, že je to nekorektné, ale nech sa pozrieme, ako ALPUS II (ALPUS) to dokáže rozpoznať. Dovolím si teraz vynechať prvé 2 kroky rozpoznávania, ktoré sú len na zovšeobecnenie. Pri identifikácií premenných samozrejme vychádzame z celého programu a nech jednotlivé premenné majú nasledovné úlohy:
pole - pole prvkov
left - ukazovateľ na prvok zľava
right - ukazovateľ na prvok sprava
Potom nasleduje porovnávanie so vzormi z báze znalostí, čo dáva výsledok, že je to rozpoznávaný ako chybný vzor. Je to veľmi elementárna chyba, čo začiatoční programátori urobia, preto je zaradený medzi chybnými vzormi. Na základe rozpoznávania systém naznačí chybu v Procese výmeny a upozorňuje, že výmenu dvoch premenných nemožno urobiť pomocou dvoch príkazov a bez pomocnej premennej.
Výsledky testovania systému ALPUS je v [3]. Študenti mali
naprogramovať algoritmus Quicksortu. Zo 78 programov bolo správnych 54. ALPUS dokázal
rozpoznať ako správnych 47 programov, čo je 87% s použitím 5 HPG grafov na tento
algoritmus. Pri použití jediného HPG grafu tento výsledok je 37 (68.8%). Úspešnosť
rozpoznávania bola podobná aj pri iných, algoritmicky opísateľných programoch.
Druhou úlohou bolo naprogramovanie jednoduchého programu, ktorý nie je algoritmicky
popísaný. Rozpoznávanie bolo pomerne malý pri týchto programoch, čo je dôsledkom
toho, že študenti používali rôzne štruktúry pri implementácií, keďže k tomu
neexistoval špecifický algoritmus. V tomto prípade lepšie výsledky dáva PROUST [3] (resp. DISCOVER), ktorý je založený na rozpoznávaní plánov,
cieľov.
Podľa [1] DISCOVER používa pseudokódový programovací jazyk
(podobný ako C). Príkazy jazyka sú nasledovné: create, put, read in, write out,
while-endwhile, if-istrue-isfalse a aritmetické a logické operácie. Pomocou
týchto základných operácií je možné naprogramovať široký sortiment programov.
Zdôrazňujem, že systém slúži na učenie programovania (a nie na vývoj zložitých
algoritmov), na čo tento inštrukčný súbor úplne postačuje.
Riešenie problému je reprezentovaný pomocou "cieľ-plán" stromu
(goal-and-plan tree) (obr. 5). Cieľ označuje postup vývoja
programu, ktorý sa očakáva od programátora. Ciele sú potom podrobnejšie popísané
plánmi, t.j. ciele mapujú na výrazy. Napríklad: každý program sa začína
deklaráciou premenných, čo je prvým cieľom. K tomu prislúchajúci plán je použitie
príkazu create s názvami premenných. Názvy premenných predstavujú ďalší
cieľ.
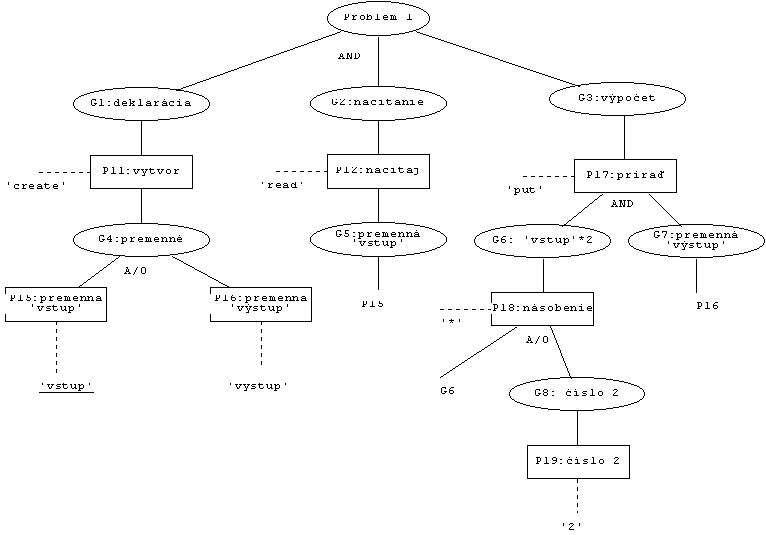
Obr 5. "cieľ-plán" strom
Uzly v stromu reprezentujú ciele a plány, a vetvy znázorňujú ich sekvenciu. Plány
a ciele sú číslované, na základe čoho DISCOVER určí ich požadované poradie.
Vetvy, ktoré vychádzajú z jedného uzla, možno spájať s logickými operáciami AND a
OR. Operácia AND znamená, že k úspechu cieľa je potrebné splniť všetky takto
spojené vetvy v danom poradí. Oproti tomu, OR znamená, že aspoň jedna vetva musí
byť splnená. Ich kombinácia A/O znamená, že je potrebné splniť všetky vetvy,
pričom ich poradie je nezávislé.
Pre každý problém existuje "cieľ-plán" strom, podľa ktorého sa usudzujú
kroky programátora. DISCOVER používa nasledovný postup pri kontrole programu:
Správa okrem vysvetlenia chyby, môže obsahovať aj návod na opravu.
Každý si môže myslieť, že porovnanie príkazov plánmi skrýva problém
identifikácie premenných. Lenže premenné sú napevno dané pri špecifikácii
problému. Potom rozpoznanie príkazov výrazne zjednodušuje. Z toho vyplýva, že aj
kontrola programov zjednodušuje, a preto systém používa len implicitne znalosti,
ktoré sú zakomponované v "cieľ-plán" strome.
Špecifikácia problému: Napíšte program, ktorý načíta číslo z klávesnice a
vypočíta jeho dvojnásobok. Na načítanie používajte premennú "vstup" a
výsledok uschovajte v premennej "výstup".
Program:
create vstup výstup
read vstup
put vstup*2 in výstup
"Cieľ-plán" strom problému je na obr. 5, ktorý je
zložitý (ťažko sa v ňom orientuje), hoci príklad je veľmi jednoduchý. Preto
DISCOVER je vhodný len na kontrolu programov s menším počtom cieľov.
V príspevku sa nachádza opis obidvoch systémov, ktoré sú založené na iných
metódach. Kým ALPUS používa produkčný systém na analýzu programov, tým DISCOVER
je založený na sledovanie modelu (znalosti sú implicitne dané). Z toho dôvodu je aj
ich použitie odlišné. Kým ALPUS dokáže analyzovať celé, už hotové programy, tým
DISCOVER to robí pri písaní zdrojového textu - podstatný rozdiel medzi systémami.
Teda DISCOVER pomáha neskúsenému programátorovi pri písaní programov, upozorňuje na
chyby, dáva ďalšie návody. Hlavná nevýhoda je vtom, že pri výskyte chyby môžeme
pokračovať až po jej oprave (pokračovať teoreticky by sme mohli, ale systém stratí
stopu). Takto používateľ je nutný pokračovať na stope, ktorú vymedzí aplikácia, s
čím zasahuje do myšlienok programátora. ALPUS detekuje chyby až po dokončení
programu, dáva voľnú ruku programátorovi pri vývoji. Tým nepotlačuje kreativitu
programátora a nenúti na neho postup, ktorý "spozná".
Znační rozdiel je aj v možnostiach rozširovania systému. Keďže ALPUS je založený
na znalostnom systéme, teda rozširovanie spočíva v pridaní nových pravidiel (HPG
graf, implementácia procesu) do bázy znalostí. To umožní aj čiastočné
rozširovanie - pridanie viac vzorov na implementáciu jedného procesu. Vieme, že
viaceré kroky možno naprogramovať s rôznymi spôsobmi (napr. cykly, zvyšovanie
hodnoty premennej, atď.). Zároveň použitie produkčného systému implicitne podporuje
kombinácie rôznych metód implementácie. Napríklad: HPG graf obsahuje 5 procesov a
báza znalostí obsahuje 3 rôzne spôsoby na implementáciu jedného procesu, teda
systém dokáže rozpoznať 35=243 rôznych spôsobov implementácie. Pridaním
jedného popisu procesu táto hodnota sa zvýši na 324.
Oproti tomu rozširovanie systému DISCOVER je neefektívny s malou účinnosťou.
Pridaním novej vetvy do grafu riešenia vzniká nová cesta (stopa) vývoja. Zdá sa, že
to je veľmi jednoduché, ale pri zložitejších grafoch vyhľadanie bodu na vloženie
novej vetvy môže byť náročné. Naviac pridaním nových vetiev graf bude menej
prehľadný (pokúsme sa predstaviť (nakresliť) graf s 324 rôznymi cestami). V [1] tvrdia, že rozširovanie nie je zložitejší, ako pri aplikácií s
produkčným systémom. S týmto názorom veľmi nesúhlasím, lebo graf pre zložitejšie
algoritmy je neprehľadný.
Kým ALPUS je vhodný na pochopenie programov, ktoré sú algoritmicky popísateľné,
DISCOVER je vhodnejší pre nealgoritmicky založené problémy. Preto by bolo vhodné v
budúcnosti uvažovať pri návrhu systémov na počítačové pochopenie programov s
kombinovaním týchto dvoch prístupov.
[1] Ramadhan, H.A.: Improving the engineering of model tracing based intelligent program diagnosis, In: IEE Proc.-Soft. Eng., Vol. 144, No. 3, Jún 1997, s. 149-161
[2] UENO, Haruki: A Generalized Knowledge-Base Approach to Comprehend Pascal and C Programs, In: P. Návrat, H. Ueno: Knowledge-Based Software Engineering, IOS Press, 1998, s. 132-139
[3] Ueno, Haruki: Concepts and Methodologies for Knowledge-Based Program Understander ALPUS, URL: http://www.rd.nacsis.ac.jp/~ueno/ronbun/alpus96/alpus96.html , 1996. (19.10.2000)
(c) Zoltán Varga, 1. inž.
Znalostné systémy
Zimný semester 2000/2001