Algoritmy pre usporiadané polia
|
|
Sekvenčné vyhľadávanie s podmienkou
|
Popis |
|
Keďže je vstupné pole zoradené, môžeme túto výhodu využiť v náš prospech. V prípade, že hľadaný prvok sa v poli nenachádza, nie je vždy potrebné prechádzať celé pole, aby sme sa túto skutočnosť dozvedeli. Ak algoritmus začne porovnávať prvky od začiatku poľa a v nejakom momente už porovnáva hľadaný prvok s prvkom, ktorý je od neho väčší, vie že ak by hľadaný prvok v poli bol, už jeho možnú pozíciu určite prehľadal.
|
Vstupy algoritmu |
|
Vstupmi sú usporiadané pole a hľadaný prvok. Ako aj v iných prípadoch, opäť môže byť veľkosť poľa zadaná dvomi spôsobmi. Buď je vstupom počet prvkov alebo je na konci poľa umiestnený ukončovací znak.
|
Princíp činnosti |
|
Podobne ako pri obyčajnom sekvenčnom prehľadávaní začne algoritmus prehľadávať prvky poľa od jeho začiatku. V tomto prípade sa však algoritmus nekončí iba v prípade, že prejde celé pole alebo nájde hľadaný prvok, ale algoritmus sa ukončí aj v prípade, že aktuálny prvok je väčší ako hľadaný. V každom cykle algoritmus zisťuje, či je aktuálny prvok menší ako hľadaný. Ak nie, potom je aktuálny prvok ešte raz porovnaný s hľadaným prvkom na rovnosť. Ak sa tieto prvky rovnajú, hľadaný prvok sa v poli nachádza. Ak sa prvky nerovnajú, znamená to, že aktuálny prvok nie je ani menší a ani rovný s hľadaným a teda sa môže hľadanie ukončiť, pretože sa hľadaný prvok v poli nenachádza. Vzhľadom na skutočnosť, že pole je zoradené a aktuálny prvok je väčší ako hľadaný, bolo by ďalšie prehľadávanie už zbytočné.
|
Výstupy algoritmu |
|
Ak bol hľadaný prvok nájdený, potom výstupom algoritmu môže byť jeho index. Ak sa algoritmus ukončil po predpísanom počte porovnaní alebo pri prehľadávaní našiel prvok väčší ako hľadaný, skončí sa neúspechom.
|
Vývojový diagram |
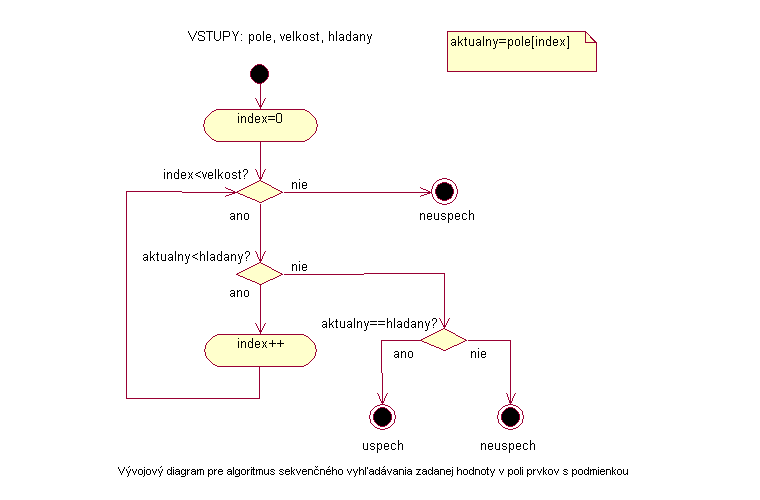 |
Implementácia |
| | //sekvencne vyhladavanie zadaneho prvku "hladany" s podmienkou
//pole "pole" s poctom prvkov "velkost" musi byt usporiadane vzostupne
//(na zaciatku pola je prvok s najmensou hodnotou)
//funkcia vracia index zadaneho prvku v poli (v pripade neuspechu vyhladavania vracia -1)
int najdi_sekv_int_podm(int* pole, int velkost, int hladany){
int index=0;
while (index < velkost) {
if (pole[index] < hladany) index++;
else {
if (pole[index]==hladany) return index;
else return -1;
}
}
return -1;
} |
| Ďalšie implementácie |
Vizualizácie |
| Príklad úspechu |
|
| Príklad neúspechu |
|
Časová zložitosť |
|
Pri úspešnom vyhľadávaní je priemerný počet vykonaných porovnaní podobne ako pri obyčajnom sekvenčnom vyhľadávaní 2*n/2, teda približne n. Výhody tohto algoritmu by sa však mali prejaviť vtedy, keď pri vyhľadávaní prvkov v poli je výsledok zväčša neúspešný. V takomto prípade totiž algoritmus neprehľadáva prvky až do konca poľa, ale skončí už vtedy, keď je zrejmé, že hľadaný prvok sa v poli nenachádza. Ak sa v poli nachádzajú prvky z rovnakého intervalu, z akého prvky vyhľadávame a ich rozdelenie je rovnomerné, počet porovnaní pri neúspešnom vyhľadávaní by mal byť tiež približne n (pri obyčajnom sekvenčnom vyhľadávaní to bolo približne 2*n). Je to preto, lebo ak sa hľadaný prvok nenachádzal na jeho predpokladanom mieste, kde by bol pri úspešnom vyhľadávaní, algoritmus sa ihneď končí.
|
Porovnanie s predchádzajúcimi algoritmami |
|
Tento algoritmus síce robí menší počet porovnaní pri neúspešnom prehľadávaní ako algoritmus využívajúci obyčajné sekvenčné vyhľadávanie, ale zďaleka nevyužíva naplno výhodu, ktorou je usporiadané vstupné pole. Omnoho efektívnejšie budú túto vlastnosť využívať nasledujúce algoritmy, ktorých opis bude teraz nasledovať.
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
