Algoritmy pre neusporiadané zoznamy
|
|
Vyhľadávanie v jednosmerne zreťazenom zozname
|
Popis |
|
Sekvenčné vyhľadávanie je základným spôsobom vyhľadávania v zozname. Prechádza postupne záznamy zoznamu od začiatku alebo konca podľa druhu zreťazenia až pokiaľ nenájde záznam obsahujúci hľadaný prvok.
|
Vstupy algoritmu |
|
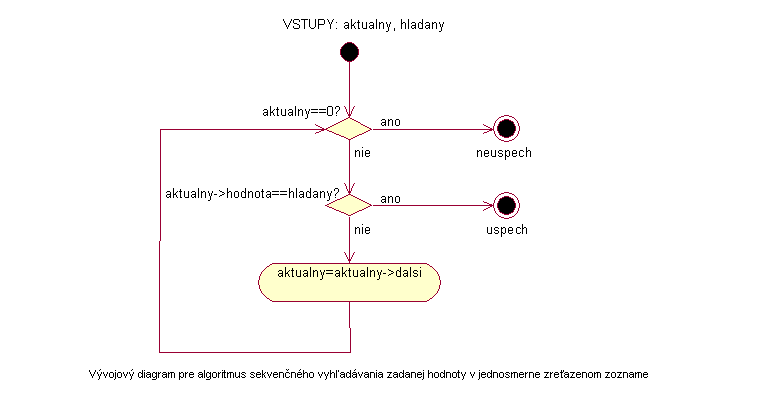
Vstupom je začiatok zreťazeného zoznamu. Zoznam môže byť zreťazený jednosmerne alebo obojsmerne ale na efektivitu tohto algoritmu to nebude mať žiaden vplyv. Dôležité je však poskytnúť algoritmu taký záznam zoznamu alebo ukazovateľ na tento záznam, aby algoritmus dokázal prehľadať celý zoznam. Ak by sme napríklad poskytli algoritmu na vstupe stredný záznam z jednosmerne zreťazeného zoznamu, všetky záznamy pred týmto záznamom by sme nemohli prehľadať, pretože by sme nenašli žiadnu informáciu o tom, kde sa tieto záznamy nachádzajú. Posledný záznam zoznamu musí obsahovať informáciu o tom, že je posledný. Zväčša to býva zabezpečené nulovým ukazovateľom na nasledujúci záznam. Ďalším vstupom je samozrejme nami hľadaný prvok.
|
Princíp činnosti |
|
Algoritmus sa nastaví na začiatok zoznamu, ktorý je vstupom tohto algoritmu. Porovná hodnotu prvku záznamu s hľadaným prvkom. V prípade zhody sa môže algoritmus ukončiť. Ak sa ale prvky nezhodujú, využije sa ukazovateľ na nasledujúci záznam, algoritmus sa presunie na neho a porovná prvok tohto záznamu s hľadaným. V prípade nezhody opäť prechádza na ďalší záznam až dovtedy, pokiaľ ešte existuje v zozname nejaký nasledujúci záznam. Ak záznam obsahuje nulový ukazovateľ, vieme, že tento záznam je v zozname posledný a algoritmus sa končí.
|
Výstupy algoritmu |
|
Podľa toho, či vyhľadávanie skončilo úspešne alebo neúspešne, môžeme poskytnúť na výstupe logickú premennú s hodnotou pravda/nepravda. Výhodnejšie však je, ak je výstupom algoritmu ukazovateľ na nájdený záznam s hľadaným prvkom. Ak sa algoritmus skončil neúspechom, je výstupom algoritmu nulový ukazovateľ.
|
Vývojový diagram |
 |
Implementácia |
| | //sekvencne vyhladavanie zadanej hodnoty "hladany" v JZ zozname od zaznamu "aktualny"
//zoznam musi byt ukonceny nulovym ukazovatelom
//funkcia vracia ukazovatel na najdeny zaznam (v pripade neuspechu vyhladavania vracia 0)
CZaznam_JZ* JZnajdi_sekv1_zaznam(int hladany, CZaznam_JZ* aktualny){
while (aktualny) {
if (aktualny->hodnota()==hladany) return aktualny;
else aktualny=aktualny->dalsi();
}
return 0;
} |
| Ďalšie implementácie |
Vizualizácie |
| Príklad úspechu |
|
| Príklad neúspechu |
|
Časová zložitosť |
|
Okrem toho, že pre každý záznam algoritmus robí porovnanie na rovnosť hľadaného prvku s prvkom v zázname, kontroluje ešte, či môžeme prejsť v prípade nezhody na nasledujúci záznam. Počet porovnaní pri neúspešnom vyhľadávaní je 2*n+1. V prípade úspešného nájdenia hľadaného prvku je v priemernom prípade počet porovnaní približne n.
|
Porovnanie s predchádzajúcimi algoritmami |
|
Tento spôsob je tým najpoužívanejším spôsobom vyhľadávania v jednosmerne zreťazenom zozname. Iné spôsoby sú zväčša nepoužiteľné, pretože vylepšenia, ktoré zvyšovali efektivitu týchto algoritmov nie sú tak ľahko realizovateľné ako tomu bolo v poli.
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
