Algoritmy pre rozptyľové tabuľky s otvoreným rozptyľovaním
|
|
Rozptyľová funkcia secondary clustering
|
Popis |
|
Problém predchádzajúcich dvoch metód bol v tom, že pri kolízii vždy ponúkajú rovnakú sekvenciu skúšania položiek. Ak teda skúsime vložiť ľubovoľný prvok do nejakej položky a tá je už plná, bez ohľadu na to, kam vlastne pôvodne patril prvok, vyskúšame ďalšiu položku v sekvencii. Popísaný problém rieši táto metóda. Nevyužíva totiž stále rovnakú sekvenciu skúšania položiek, ale sekvencia skúšania závisí od prvej skúšanej položky.
|
Vstupy algoritmu |
|
Vstupmi sú rozptyľová tabuľka so zadaným počtom riadkov a vyhľadávaná hodnota v tabuľke.
|
Príklad rozptylovej funkcie a sekvencia skúšaných položiek |
|
h(k) = [f(k) + i*p(k)] mod 13
p(k) = (f(k) + 4) mod 13 pre p(k)!=0, inak p(k)=1
2, 8, 1, 7, 0, 6, 12, 5, 11, 4, 10, 3, 9, 2, ...
|
Výstupy algoritmu |
|
V prípade úspešného vyhľadávania je výstupom index riadku v tabuľke, kde bola vyhľadávaná hodnota nájdená. V prípade že pri hľadaní nájdeme prázdnu položku alebo počet vykonaných pokusov je rovný veľkosti tabuľky, algoritmus sa končí neúspechom a návratová hodnota je -1.
|
Vývojový diagram |
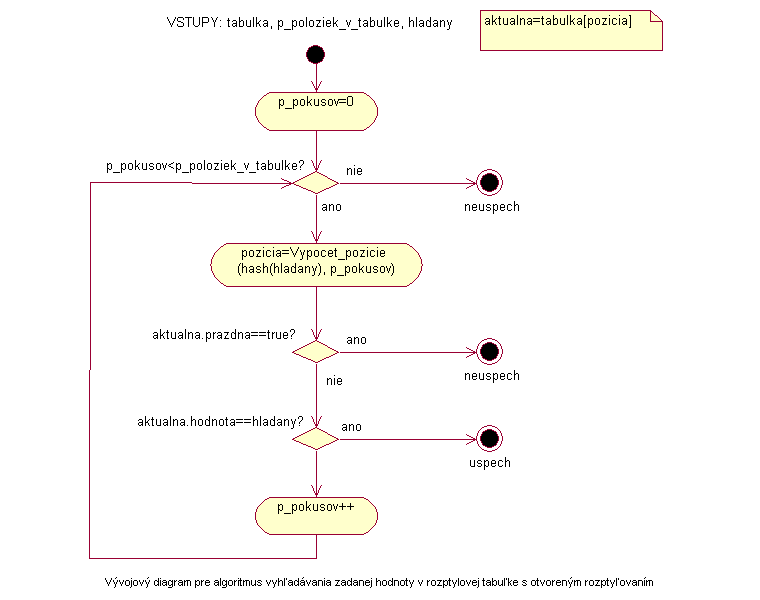 |
Implementácia |
| | //najdenie zadanej hodnoty "hodnota" v rozptylovej tabulke "tabulka"
//s otvorenym rozptylovanim s poctom riadkov "p_riadkov"
//funkcia vracia index polozky v ktorej bola hodnota najdena (v pripade neuspechu vracia -1)
int najdi_OR(Criadok_OR* tabulka, int p_riadkov, int hodnota, int sposob) {
int pokus=0;
while (pokus < p_riadkov) {
int riadok = funkcia_OR(p_riadkov, hodnota, pokus, sposob);
if (tabulka[riadok].prazdna()) return -1;
else if (tabulka[riadok].hodnota()==hodnota) return riadok;
else pokus++;
}
return -1;
} |
| Úplná implementácia |
Vizualizácie |
| Príklad úspechu pre metódu secondary clustering |
|
| Príklad neúspechu pre metódu secondary clustering |
|
|
