|
|
Grafy a tabuľky |
| Sekvenčné vyhľadávanie so zarážkou
|
Priemerné počty porovnaní vybraných implementácií |
//sekvencne vyhladavanie zadaneho prvku "hladany" s pomocou zarazky
//funkcia vracia index zadaneho prvku v poli (v pripade neuspechu vyhladavania vracia -1)
template < class T, int velkost_ >
int CPole < T, velkost_ > ::najdi_sekv_index_zarazka(T hladany, int p_prvkov){
if (++p_c_porovnani_ && p_prvkov >= velkost_) {
cout << endl << "Na konci pola nie je miesto pre zarazku" << endl;
exit(-1);
}
pole_[p_prvkov]=hladany;
int index=0;
while (++p_b_porovnani_ && pole_[index]!=hladany) {++p_a_cyklov_; index++;}
if (++p_a_porovnani_ && index < p_prvkov) return index;
else return -1;
} |
| Počet porovnaní, cyklov a času trvania algoritmu pre úspešné vyhľadávanie. |
| počet prvkov v poli |
p_a_porovnani_ |
p_b_porovnani_ |
p_c_porovnani_ |
p_a_cyklov_ |
čas |
| 10 |
1,000 |
5,500 |
1,000 |
4,500 |
0,0905 |
| 100 |
1,000 |
50,50 |
1,000 |
49,50 |
0,4041 |
| 1.000 |
1,000 |
500,5 |
1,000 |
499,5 |
3,575 |
| 10.000 |
1,000 |
5000,5 |
1,000 |
4999,5 |
34,90 |
| 100.000 |
1,000 |
50000,5 |
1,000 |
49999,5 |
385,6 |
|
Ako môžeme vidieť, skutočne sa zmenšil počet porovnaní. Pre priemerný prípad úspešného vyhľadávania je rádovo n/2. Počet cyklov je tiež približne rovný polovici dĺžke vstupného poľa. |
| |
| Počet porovnaní, cyklov a času trvania algoritmu pre neúspešné vyhľadávanie s p=0,9. |
| počet prvkov v poli |
p_a_porovnani_ |
p_b_porovnani_ |
p_c_porovnani_ |
p_a_cyklov_ |
čas |
| 10 |
1,000 |
9,800 |
1,000 |
8,800 |
0,1283 |
| 100 |
1,000 |
96,83 |
1,000 |
95,83 |
0,7276 |
| 1.000 |
1,000 |
955,7 |
1,000 |
954,7 |
6,719 |
| 10.000 |
1,000 |
9556,0 |
1,000 |
9555,0 |
66,10 |
| 100.000 |
1,000 |
97737,0 |
1,000 |
97736,0 |
915,4 |
|
Pre zväčša neúspešné vyhľadávanie je počet porovnaní a teda aj cyklov rádovo n. |
| |
| |
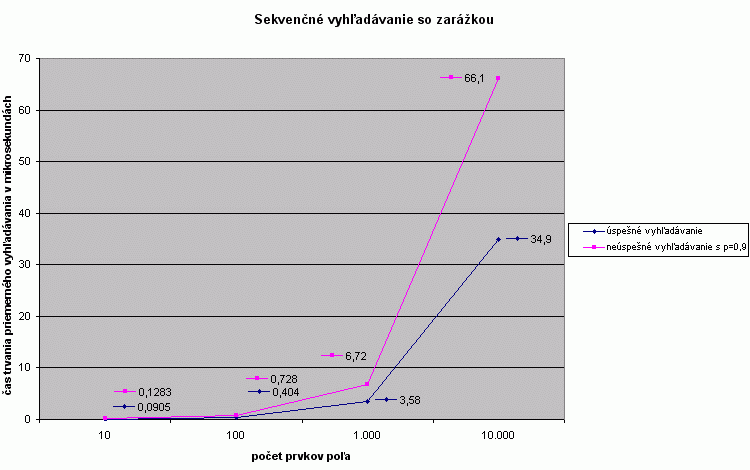
Závislost dĺžky času trvania algoritmu od veľkosti vstupného pola |
Algoritmus má opäť lineárnu závislosť dĺžky trvania od veľkosti vstupného poľa. Odchýlky sú spôsobené pre malé polia volaním funkcie a pre veľké polia stránkovaním. |
 |
| |
10 |
100 |
1.000 |
10.000 |
100.000 |
| úspešné vyhľadávanie |
0,0905 |
0,4040 |
3,580 |
34,90 |
386,0 |
| neúspešné vyhľadávanie s p=0,9 |
0,1283 |
0,7280 |
6,720 |
66,10 |
915,0 |
|
| |
| |
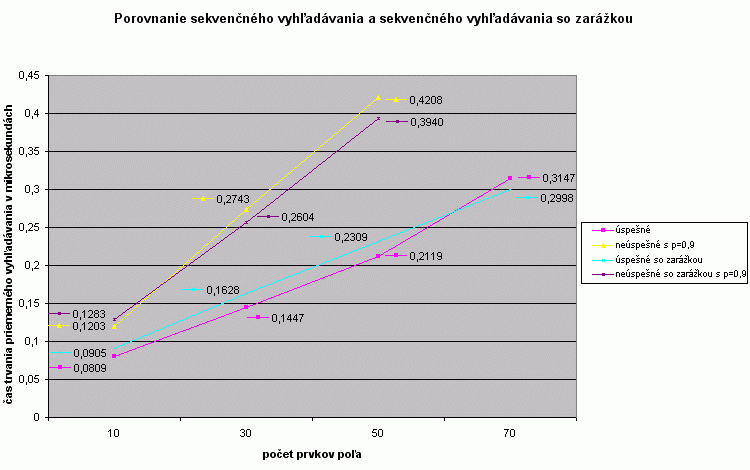
Porovnanie algoritmu s predchádzajúcimi algoritmami |
Od sekvenčného vyhľadávania so zarážkou sme si sľubovali na základe zmenšenia počtu porovnaní aj zrýchlenie vyhľadávania. To však nenastalo v takej miere, ako sme to asi očakávali. Je to spôsobené tým, že počet cyklov je pre oba algoritmy rovnaký. Napriek tomu je z nameraných hodnôt vidieť, že pre veľkosti poľa väčšie ako približne 15 prvkov pre úspešné vyhľadávanie a asi 60 prvkov pre zväčša neúspešné vyhľadávanie je sekvenčný algoritmus so zarážkou rýchlejší a s narastajúcou veľkosťou poľa sa jeho náskok pred obyčajným sekvenčným vyhľadávaním zväčšuje. Pre menšie polia je pomalejší z dôvodu kontroly miesta na konci poľa a následným umiestňovaním zarážky. |
 |
| |
10 |
30 |
50 |
70 |
100 |
| úspešné sekvenčné |
0,0809 |
0,1447 |
0,2119 |
0,3147 |
0,429 |
| neúspešné sekvenčné s p=0,9 |
0,1203 |
0,2743 |
0,4208 |
0,5687 |
0,79 |
| úspešné so zarážkou |
0,0905 |
0,1628 |
0,2309 |
0,2998 |
0,404 |
| neúspešné so zarážkou s p=0,9 |
0,1283 |
0,2569 |
0,3940 |
0,5061 |
0,728 |
|
| |
| |
| Poznámka: Algoritmy boli testované na počítači s procesorom AMD Athlon(tm) XP 1700+ a s 256 MB operačnou pamäťou pod operačným systémom Windows XP. Všetky časy uvedené v tabuľke sú v mikrosekundách. |
