Algoritmy pre neusporiadané polia
|
|
Sekvenčné vyhľadávanie
|
Popis |
|
Aby algoritmus mohol odpovedať na dopyt používateľa, či sa hľadaný prvok v poli nachádza alebo nie, musí prezrieť všetky prvky, ktoré sa v poli nachádzajú a porovnať ich s hľadaným prvkom. Tento algoritmus prehľadáva všetky prvky poľa postupne od začiatku až po nájdenie hľadaného prvku alebo po prejdenie celého obsahu poľa.
|
Vstupy algoritmu |
|
Vstupmi tohto algoritmu sú pole prvkov a hľadaný prvok. Ďalším vstupom tohto algoritmu môže byť počet prvkov v poli alebo si algoritmus sám kontroluje, či aktuálny prvok nie je ukončovacím znakom poľa. Ak je pole ukončené ukončovacím znakom, nie je počet prvkov poľa ako ďalší vstup potrebný.
|
Princíp činnosti |
|
Na začiatku sa algoritmus nastaví na prvý (nultý prvok poľa) a porovná ho s hľadaným prvkom. Ak sa prvky líšia, prejde na ďalší prvok poľa a takto až po koniec poľa alebo po nájdenie hľadaného prvku. V prípade nájdenia prvku sa algoritmus sekvenčného vyhľadávania končí. Ak sa pri hľadaní dostane až na koniec poľa, znamená to, že v poli hľadaný prvok nie je. Indikátorom toho, že je už na konci poľa môžu byť tieto dve nasledujúce udalosti. Je to urobenie predpísaného množstva cyklov alebo nájdenie ukončovacieho znaku v poli.
|
Výstupy algoritmu |
|
Výstupom algoritmu je pozícia hľadaného prvku v poli. Ak teda nájde hľadaný prvok v poli na i-tom mieste, výstup bude index i. Ak prvok v poli nenájde, algoritmus vráti takú hodnotu, ktorá nemôže byť indexom žiadneho prvku v poli (napr. -1).
|
Vývojový diagram |
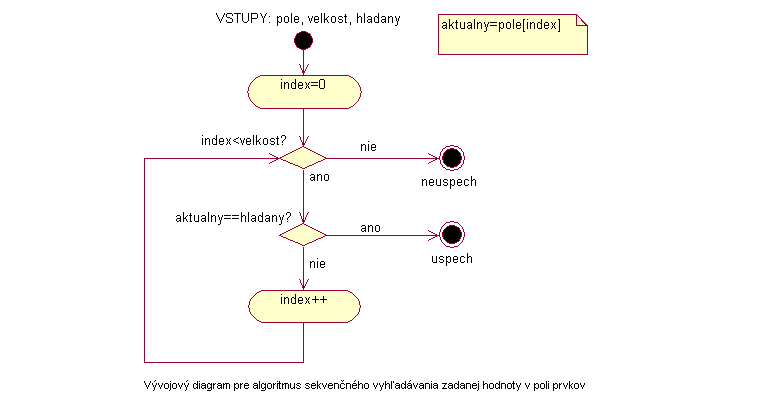 |
Implementácia |
| | //sekvencne vyhladavanie zadaneho prvku "hladany" v poli "pole" s poctom prvkov "velkost"
//funkcia vracia index zadaneho prvku v poli (v pripade neuspechu vyhladavania vracia -1)
int najdi_sekv_index(int* pole, int velkost, int hladany){
int index=0;
while (index < velkost) {
if (pole[index]==hladany) return index;
index++;
}
return -1;
} |
| Ďalšie implementácie |
Vizualizácie |
| Príklad úspechu |
|
| Príklad neúspechu |
|
Časová zložitosť |
|
Keďže algoritmus porovnáva každý prvok poľa s hľadaným prvkom, je počet porovnaní v najhoršom prípade rovný dĺžke poľa. To je v prípade, keď hľadaný prvok v poli nie je alebo je na poslednom mieste. Dĺžku poľa budeme ďalej označovať ako n. Aby ale neporovnával aj prvky, ktoré sa nachádzajú až za koncom vstupného poľa musí pred každým porovnaním na hľadanú hodnotu vykonať ešte jedno porovnanie. Odpoveďou tohto porovnania je, či sa ešte stále nachádza vo vstupnom poli. Pokiaľ teda hľadaný prvok nenájde niekde v poli, bude týchto porovnaní n+1. Posledný krát bude výsledok porovnania neúspešný. Celkový počet porovnaní tohto algoritmu je v najhoršom prípade 2*n+1. Počet porovnaní pre úspešné vyhľadávanie tohto algoritmu je 1+n, teda približne n. Je to z toho dôvodu, že hľadaný prvok sa môže s rovnakou pravdepodobnosťou nachádzať ako na začiatku, tak aj na konci poľa. Je teda zrejmé, že ak urobíme priemer všetkých hľadaní (hľadaný prvok je vždy na inej pozícii v poli), dostaneme, že v priemernom prípade sa prvok nachádza uprostred poľa. Kým ho teda algoritmus nájde, urobí približne n porovnaní.
|
Porovnanie s predchádzajúcimi algoritmami |
|
Tento algoritmus je základom všetkých ostatných. Neponúka žiadne špeciálne postupy či vylepšenia a slúži skôr len na porovnanie alebo ako odrazový mostík k algoritmom, ktoré sú vo vyhľadávaní za rovnakých vstupných podmienok efektívnejšie.
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
