Algoritmy pre neusporiadané polia
|
|
Sekvenčné vyhľadávanie so zarážkou
|
Popis |
|
Jednou z nevýhod predchádzajúceho algoritmu bolo to, že pred každým porovnaním, či sa aktuálny prvok rovná hľadanému, musel ešte urobiť porovnanie, ktoré rozhodlo o tom, či sa nachádza aktuálny prvok vo vstupnom poli. Tento algoritmus zjednotil tieto dve porovnania do jedného. Umiestni na koniec poľa hľadaný prvok a tak zabezpečí, že hľadaný prvok vždy nájde. Ak vo vstupnom poli tento prvok nebol, nájde ho na jeho konci, ukončí sa a tak nebude prehľadávať aj prvky, ktoré sa nachádzajú až za poľom.
|
Vstupy algoritmu |
|
Vstupmi pre tento algoritmus sú hľadaný prvok, vstupné pole prvkov, jeho dĺžka a skutočný počet prvkov v poli. Posledný vstup je potrebný na správne umiestnenie zarážky.
|
Princíp činnosti |
|
Algoritmus najprv umiestni na koniec vstupného poľa hľadaný prvok. Samozrejme je potrebné skontrolovať, či pole nie je naplnené až po svoj koniec prvkami poľa. V takomto prípade už ale v poli nezostane miesto na umiestnenie zarážky a algoritmus nie je možné vykonať. Po úspešnom umiestnení zarážky algoritmus začne prehľadávať pole od jeho začiatku (nultý prvok) až po nájdenie hľadaného prvku. Po nájdení hľadaného prvku sa algoritmus skončí. Pred jeho úplným ukončením však musíme ešte odstrániť zarážku, ak je to potrebné. Ak sme napríklad zarážkou prepísali ukončovací znak poľa, musíme ho znova na toto miesto zapísať.
|
Výstupy algoritmu |
|
Keďže pri hľadaní algoritmus vždy uspeje, výstup algoritmu závisí od toho, na ktorej pozícii v poli je hľadaný prvok nájdený. Ak to bolo niekde v poli, je hľadanou hodnotou práve index tohto prvku. Ak je hľadaný prvok nájdený až na mieste, kam ho algoritmus sám zapísal ako zarážku, hľadaný prvok sa v poli nenachádzal a z návratovej hodnoty musí byť tento fakt zrejmí.
|
Vývojový diagram |
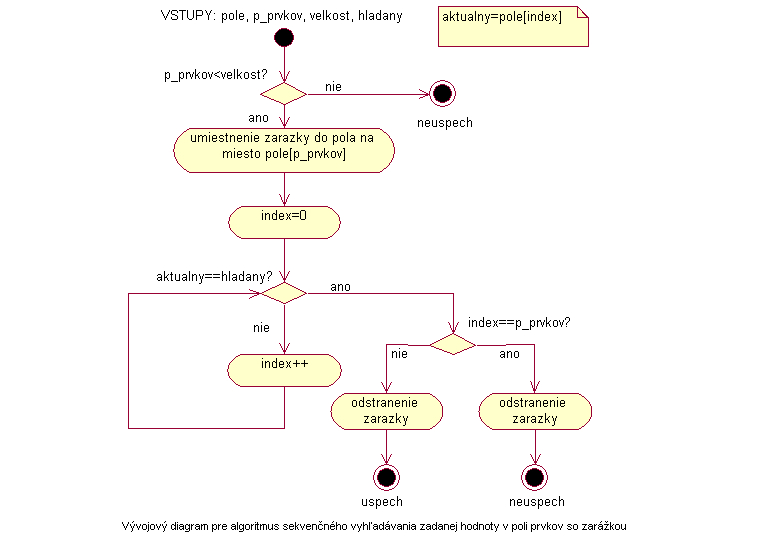 |
Implementácia |
| | //sekvencne vyhladavanie zadaneho prvku "hladany" s pomocou zarazky v poli "pole"
//s velkostou "velkost" a poctom prvkov "p_prvkov"
//funkcia vracia index zadaneho prvku v poli (v pripade neuspechu vyhladavania vracia -1)
int najdi_sekv_index_zarazka(int* pole, int velkost, int p_prvkov, int hladany){
if(p_prvkov >= velkost) {
cout << endl << "Na konci pola nie je miesto pre zarazku" << endl;
exit(-1);
}
pole[p_prvkov]=hladany;
int index=0;
while (pole[index] != hladany) index++;
if (index < p_prvkov) return index;
return -1;
} |
| Ďalšie implementácie |
Vizualizácie |
| Príklad úspechu |
|
| Príklad neúspechu |
|
Časová zložitosť |
|
Keďže algoritmus vykonáva počas každého cyklu iba porovnanie, či sa daný prvok rovná hľadanému, je počet porovnaní v najhoršom prípade iba n+1. Počet porovnaní pre úspešné vyhľadávanie je potom (n+1)/2. Daňou za zmenšenie počtu porovnaní je réžia spojená s umiestňovaním a prípadným odstraňovaním zarážky.
|
Porovnanie s predchádzajúcimi algoritmami |
|
Tým, že sa zmenší počet porovnaní a réžia spojená s umiestňovaním a prípadným odstraňovaním zarážky nie je veľká, môže byť dosiahnuté zrýchlenie vyhľadávania. Drobnou nevýhodou však je, že na konci poľa musí zostať miesto pre zarážku.
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
