Algoritmy pre usporiadané polia
|
|
Interpolačné vyhľadávanie
|
Popis |
Tak ako algoritmus binárneho delenia, tak aj algoritmus interpolačného vyhľadávania neprechádza pole sekvenčne, ale pozíciu aktuálneho prvku vypočítava a podľa jeho hodnoty ďalej pokračuje v prehľadávaní poľa. Výpočet tentoraz nie je taký jednoduchý ako pri binárnom vyhľadávaní, ale vychádza z trochu inej myšlienky. Keď prehľadávame telefónny zoznam a hľadáme niekoho, koho priezvisko sa začína na písmeno B, nepozrieme sa do stredu, ale nejako intuitívne otvoríme zoznam niekde blízko začiatku. Toto zohľadňuje práve tento algoritmus.
Vypočítanie pozície aktuálneho prvku
poz_akt_prvku = lava_hranica +
(hladany_prvok – prvok_na_lavej_hranici) * (prava_hranica – lava_hranica) /
(prvok_na_pravej_hranici – prvok_na_lavej_hranici)
Vzorec na nájdenie pozície aktuálneho prvku v poli vychádza z rovnomerného rozdelenia prvkov v poli.
|
Vstupy algoritmu |
|
Vstupmi algoritmu sú znova usporiadané pole prvkov, hľadaný prvok a počet prvkov v poli. Ten je potrebný pre odhad, kde približne by sa náš hľadaný prvok mal v poli nachádzať.
|
Princíp činnosti |
|
Algoritmus vypočíta podľa vzorca pozíciu v poli, kde sa najpravdepodobnejšie nachádza hľadaný prvok. Ak sa trafil presne a hľadaný prvok sa tu nachádza, potom sa algoritmus končí. Inak, podobne ako pri binárnom vyhľadávaní sa podľa výsledku porovnania aktuálneho prvku s hľadaným pokračuje buď v ľavej alebo pravej časti poľa. Ak je hľadaný prvok menší ako ten na aktuálnej pozícii, stane sa prvok naľavo od aktuálneho pravou hranicou poľa. Ak je hľadaný prvok väčší ako aktuálny prvok, stane sa prvok napravo od aktuálneho prvku ľavou hranicou nového poľa. Znova sa potom vypočíta predpokladaná možná pozícia hľadaného prvku v poli a pokračuje sa v približovaní k jeho skutočnej pozícii. Pole sa týmto spôsobom delí až dovtedy, pokiaľ sa nenájde hľadaný prvok alebo sa nová hranica poľa neurčí tak, že sa prvok v poli nemôže nachádzať.
|
Výstupy algoritmu |
|
Ak sa algoritmus neukončí nájdením hľadaného prvku, ukončí sa vo chvíli, keď je prvok na ľavej hranici poľa väčší ako hľadaný alebo prvok na pravej hranici poľa je menší ako hľadaný prvok. V týchto prípadoch sa algoritmus končí neúspechom. Výstupom algoritmu je index hľadaného prvku alebo –1, ak sa hľadaný prvok v poli nenachádzal.
|
Vývojový diagram |
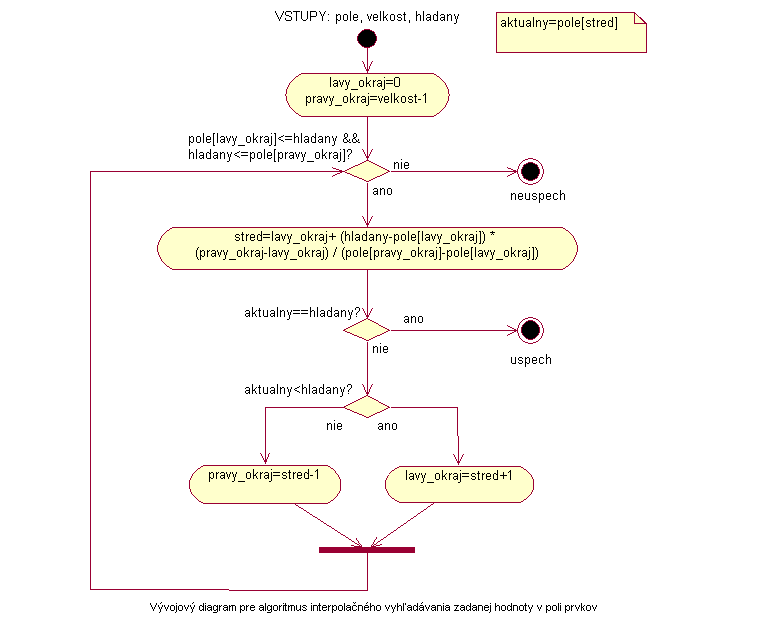 |
Implementácia |
| | //interpolacne vyhladavanie zadaneho prvku "hladany" medzi lavym "lavy_o"
//a pravym "pravy_o" okrajom zadaneho pola "pole", ktore musi byt usporiadane vzostupne
//(na zaciatku pola je prvok s najmensou hodnotou)
//funkcia vracia index zadaneho prvku v poli (v pripade neuspechu vyhladavania vracia -1)
int najdi_interpol_index(int* pole, int lavy_o, int pravy_o, int hladany){
while (pole[lavy_o] <= hladany && hladany <= pole[pravy_o]) {
float menovatel=(pole[pravy_o]-pole[lavy_o]);
if (menovatel==0) {
if (pole[lavy_o]==hladany) return lavy_o;
else return -1;
}
int stred = lavy_o + (hladany - pole[lavy_o]) * ((pravy_o-lavy_o) / menovatel);
if (pole[stred]==hladany) return stred;
else if (pole[stred] < hladany) lavy_o=stred+1;
else pravy_o=stred-1;
}
return -1;
} |
| Ďalšie implementácie |
Vizualizácie |
| Príklad úspechu |
|
| Príklad neúspechu |
|
Časová zložitosť |
|
Počet porovnaní sa nedá presne určiť, pretože veľmi závisí od rozdelenia čísiel v poli a efektivity použitého vzorca. Časovo najnáročnejšou časťou algoritmu je výpočet novej aktuálnej pozície.
|
Porovnanie s predchádzajúcimi algoritmami |
|
Nevýhodou tohto algoritmu je náročný výpočet nového aktuálneho prvku. Zatiaľ čo pri binárnom vyhľadávaní nám stačilo delenie číslom 2 (ľahko realizovateľným), tu potrebujeme okrem samotného delenia (a to zložitejšieho) navyše aj násobenie. Prednosťou tohto algoritmu je rýchlejšie priblíženie sa k hľadanému prvku pri vhodnom rozdelení prvkov v poli. Ak však nie je rozdelenie prvkov v poli približne rovnomerné, ale napríklad exponenciálne, vzorec, z ktorého vychádzame sa stáva skôr príťažou ako urýchlením v hľadaní a tento algoritmus stráca na efektivite.
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
