Algoritmy pre usporiadané polia
|
|
Fibbonacciho vyhľadávanie
|
Popis |
|
Tento algoritmus je založený na prirodzenom delení prvkov poľa. Opäť porovnáva vypočítaný aktuálny prvok s hľadaným a podľa toho ďalej pokračuje vo vyhľadávaní hľadaného prvku. Pole delí podľa prvkov Fibbonacciho postupnosti, ktoré musí nejakým spôsobom poznať. Preto bývajú tieto prvky často vypočítavané pred zahájením samotného hľadania.
Prvky Fibbonacciho postupnosti
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, ...
|
Vstupy algoritmu |
|
Vstupmi sú tak ako v predchádzajúcich dvoch prípadoch opäť zoradené pole prvkov, hľadaný prvok a počet prvkov v poli. Počet prvkov v poli však musí byť o 1 menší ako niektoré z Fibbonacciho čísiel. Keďže algoritmus používa pri vyhľadávaní prvky Fibbonacciho postupnosti, môžeme považovať za vstup aj túto postupnosť, ktorá ale samozrejme môže byť vypočítaná aj pri spustení algoritmu.
|
Princíp činnosti |
|
Počet prvkov v poli je číslo o 1 menšie ako nejaké číslo (F(k)) vo Fibbonacciho postupnosti. Algoritmus začne hľadaný prvok porovnávať s prvkom na (F(k-1)) pozícii vo vstupnom poli. Ak sa prvky rovnajú, našiel hľadaný prvok a algoritmus sa končí. Inak, ak je hľadaný prvok menší ako aktuálny, vie že počet prvkov v poli od začiatku vstupného poľa po aktuálny prvok je (F(k-1)) – 1 a pre ďalšie vyhľadávanie zoberie do úvahy už len toto pole a aktuálnym prvkom v poli sa stane predchádzajúci prvok z Fibbonacciho postupnosti, teda prvok na pozícii (F(k-2)). Ak je hľadaný prvok väčší ako aktuálny, potom ďalej berie do úvahy už len pole od pozície (F(k-1)) + 1 po koniec poľa, teda najviac po pozíciu (F(k)) – 1 a za aktuálny prvok vezme prvok z tohto poľa na pozícii (F(k-2)). Takto postupuje pokiaľ nenájde hľadaný prvok alebo sa pri vyhľadávaní nedostane k veľkosti poľa 1. Ak ani v takomto poli sa prvok nenachádza, potom sa nenachádza ani v celom poli.
|
Výstupy algoritmu |
|
V prípade úspechu môže byť výstupom algoritmu index prvku v poli. V prípade, že algoritmus delí pole stále na menšie a dostane sa už k veľkosti poľa 1 a ani v tomto poli sa hľadaná hodnota nenachádza, nemôže už pole ďalej deliť a hľadať ďalej zadanú hodnotu. V takomto prípade sa končí neúspechom.
|
Vývojový diagram |
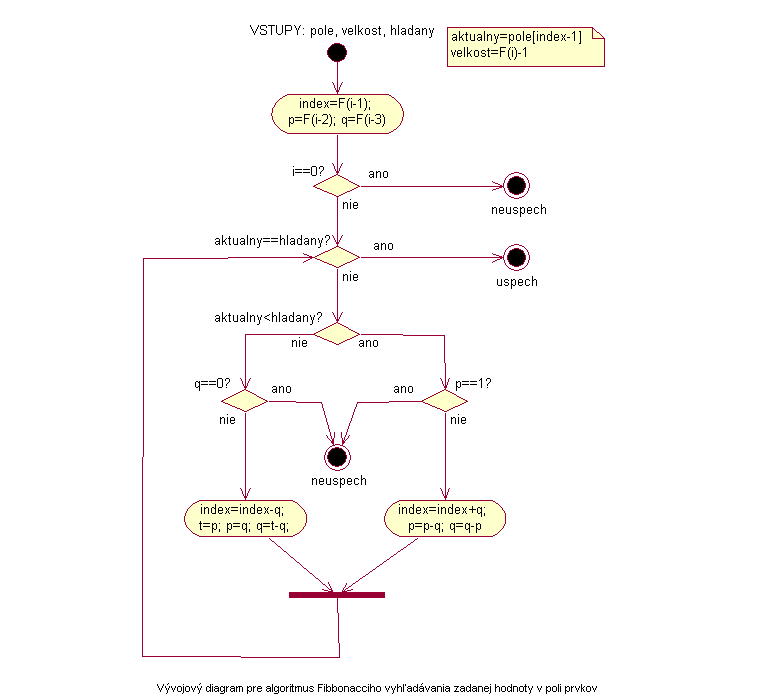 |
Implementácia |
| | //fibbonachiho vyhladavanie zadaneho prvku "hladany"
//pole "pole" s poctom prvkov "velkost" musi byt usporiadane vzostupne
//(na zaciatku pola je prvok s najmensou hodnotou)
//funkcia vracia index zadaneho prvku v poli (v pripade neuspechu vyhladavania vracia -1)
int najdi_fib_index(int* pole, int velkost, int hladany){
int fib_pole[MAX_DLZKA_FIB_RADU];
fib_pole[0]=0;
fib_pole[1]=1;
int index=1;
while(index < MAX_DLZKA_FIB_RADU && fib_pole[index] < velkost) {
index++;
fib_pole[index] = fib_pole[index-2] + fib_pole[index-1];
}
int i=fib_pole[index-1];
int p=fib_pole[index-2];
int q=fib_pole[index-3];
if (i==0) return -1;
while(true){
if (pole[i-1]==hladany) return i-1;
else if (pole[i-1] < hladany) {
if (p==1) return -1;
else {
i=i+q;
p=p-q;
q=q-p;
}
}
else {
if (q==0) return -1;
else {
i=i-q;
int t=p;
p=q;
q=t-q;
}
}
}
} |
| Ďalšie implementácie |
Vizualizácie |
| Príklad úspechu |
|
| Príklad neúspechu |
|
Časová zložitosť |
|
Priemerná časová zložitosť tohto algoritmu je podobne ako pri binárnom delení podľa [8] rádovo (log(2) n) - 1 a v najhoršom prípade približne log(2) n.
|
Porovnanie s predchádzajúcimi algoritmami |
|
Z rozloženia prvkov Fibbonacciho postupnosti podľa [6] vyplýva, že tento algoritmus bude vždy v priemernom prípade časovo náročnejší ako algoritmus binárneho delenia. Výsledky tohto algoritmu by však mali byť porovnateľné s výsledkami binárneho a interpolačného vyhľadávania. Fibbonacciho vyhľadávanie nám ukazuje ďalšiu možnú postupnosť pri hľadaní zadaného prvku. Jeho hlavnou výhodou je absencia akéhokoľvek delenia a násobenia. Preto sa využíva najmä tam, kde je z časových dôvodov vhodné vyhnúť sa týmto aritmetickým operáciám. Bližšie sa tomuto algoritmu venuje [6].
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
