Algoritmy pre rozptyľové tabuľky s otvoreným rozptyľovaním
|
|
Rozptyľová funkcia double hashing
|
Popis |
|
Posledným typom rozptyľovania, ktorý si opíšeme je dvojité rozptyľovanie. Zatiaľ sme pri neúspešnom rozptyľovaní vždy pri ďalšom pokuse o nájdenie voľnej položky použili variantu pôvodnej rozptylovej funkcie. Nič nám ale nebráni v tom, použiť rozptylovú funkciu úplne inú. V prvom kroku použijeme prvú rozptylovú funkciu a pri jej neúspechu následne druhú, úplne inú rozptylovú funkciu. Ak ani druhá funkcia neuspeje pri nájdení voľnej položky v tabuľke, potom ďalej už môžeme používať jej obmeny, tak ako sme si to ukázali pri prvých štyroch príkladoch alebo tieto dve funkcie striedať.
|
Vstupy algoritmu |
|
Vstupmi sú rozptyľová tabuľka so zadaným počtom riadkov a vyhľadávaná hodnota v tabuľke.
|
Výstupy algoritmu |
|
V prípade úspešného vyhľadávania je výstupom index riadku v tabuľke, kde bola vyhľadávaná hodnota nájdená. V prípade že pri hľadaní nájdeme prázdnu položku alebo počet vykonaných pokusov je rovný veľkosti tabuľky, algoritmus sa končí neúspechom a návratová hodnota je -1.
|
Vývojový diagram |
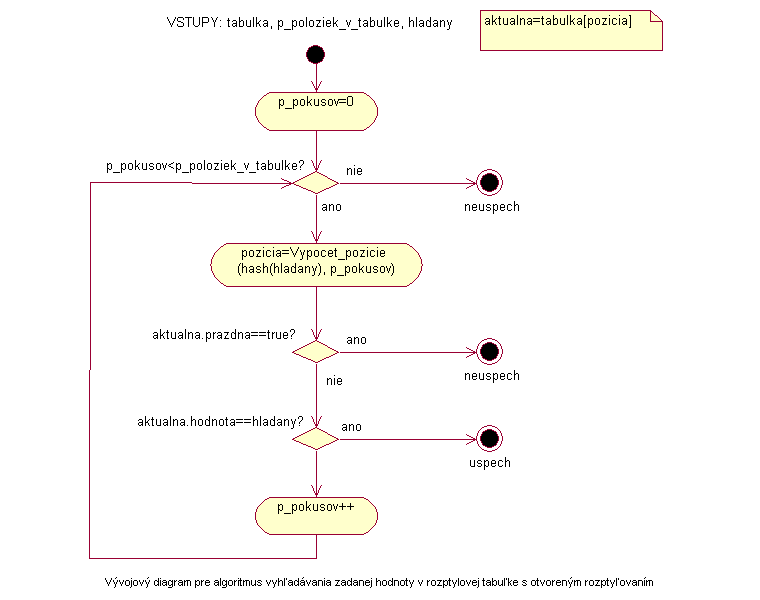 |
Implementácia |
| | //najdenie zadanej hodnoty "hodnota" v rozptylovej tabulke "tabulka"
//s otvorenym rozptylovanim s poctom riadkov "p_riadkov"
//funkcia vracia index polozky v ktorej bola hodnota najdena (v pripade neuspechu vracia -1)
int najdi_OR(Criadok_OR* tabulka, int p_riadkov, int hodnota, int sposob) {
int pokus=0;
while (pokus < p_riadkov) {
int riadok = funkcia_OR(p_riadkov, hodnota, pokus, sposob);
if (tabulka[riadok].prazdna()) return -1;
else if (tabulka[riadok].hodnota()==hodnota) return riadok;
else pokus++;
}
return -1;
} |
| Úplná implementácia |
|
