Algoritmy pre reťazce
|
|
Vyhľadávanie algoritmom Brute force
|
Popis |
|
Aby algoritmus vedel odpovedať na dopyt užívateľa, či sa zadaný vzor nachádza v reťazci, musí postupne prejsť celý reťazec od začiatku až po koniec a porovnávať vzor znak po znaku so znakmi v reťazci.
|
Vstupy algoritmu |
|
Vstupom sú zadaný hľadaný vzor a reťazec, v ktorom vzor vyhľadávame. V počítačovej reprezentácii sú vstupmi iba ukazovatele na vzor a reťazec. Vzor a aj reťazec musia byť ukončené ukončovacím znakom alebo musí byť zadaný počet znakov, ktoré obsahujú. Počet znakov vzoru musí byť menší ako počet znakov v reťazci. Vhodnejším vstupom je priamo počet znakov, pretože tento údaj bude algoritmus k svojmu fungovaniu potrebovať.
|
Princíp činnosti |
|
Algoritmus sa nastaví na začiatok vzoru a aj reťazca a uchová si začiatočnú pozíciu v reťazci, od ktorej sa začína porovnávanie. Skontroluje, či sa nulté znaky rovnajú. Ak áno, nastaví sa aj vo vzore a aj v reťazci na nasledujúci znak a tie opäť porovná. Ak sa opäť rovnajú postupuje takto dovtedy, pokiaľ nedosiahne počet úspešných porovnaní, ktorý sa rovná dĺžke vzoru alebo dokedy nenájde odlišnosť v porovnávaných znakoch. V prípade, že počet dosiahnutých úspešných porovnaní je rovný dĺžke vzoru, našiel zadaný vzor v reťazci a algoritmus sa končí. Ak sa porovnávané znaky pri ľubovoľnom porovnaní nezhodujú, nastaví sa na začiatok vzoru a v reťazci sa nastaví na znak nasledujúci po tom, ktorého pozíciu si na začiatku porovnávania uchoval. Aktuálna pozícia bude novou začiatočnou pozíciou. Ak teda porovnanie zlyhá hneď pri prvom pokuse, nastaví sa na nasledujúci znak. Ak porovnanie zlyhá napr. po 10 úspešných porovnaniach, vrátime sa o 10–1 znakov späť. Algoritmus sa končí vtedy, ak sa pri prehľadávaní reťazca dostane na pozíciu, kedy už nie je možné aby sa hľadaný vzor v reťazci nachádzal.
|
Výstupy algoritmu |
|
Ak sa algoritmu podarí urobiť bez prerušenia počet úspešných porovnaní rovný dĺžke vzoru, algoritmus sa končí úspechom. Výstupom je uchovaná začiatočná pozícia úspešných porovnaní v reťazci. Ak pri prehľadávaní zostane algoritmu menej znakov do konca reťazca ako potrebných úspešných porovnaní pre zhodu vzoru a reťazca, algoritmus končí neúspechom a vracia napr. hodnotu –1 (táto hodnota nemôže byť indexom žiadneho prvku reťazca).
|
Vývojový diagram |
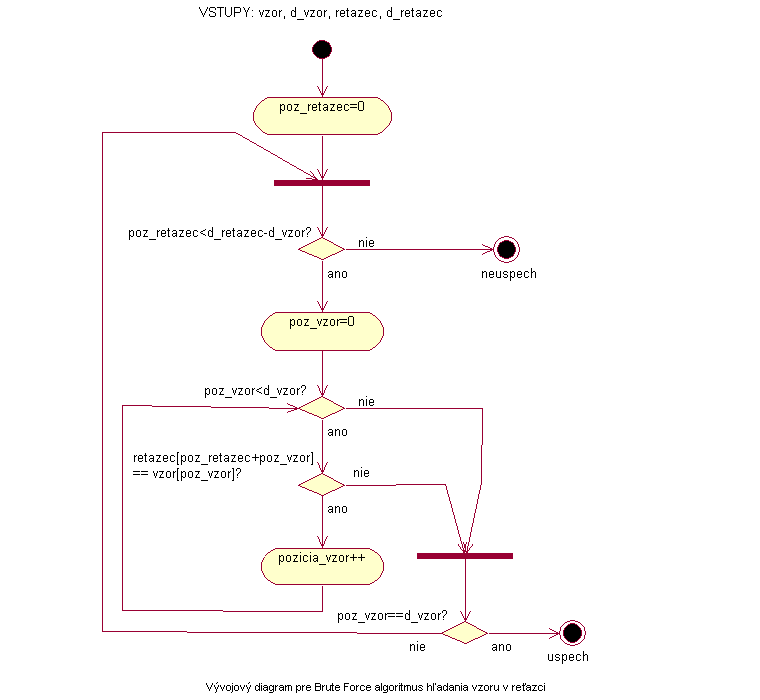 |
Implementácia |
| | //obycajne sekvencne vyhladavanie zadaneho vzoru "vzor" s poctom znakov "dlzka_v"
//v retazci "retazec" s poctom znakov "dlzka_r"
//funkcia vracia index prveho znaku najdeneho vzoru v retazci
//(v pripade neuspechu vyhladavania vracia -1)
int najdi_sekv(char* vzor, int dlzka_v, char* retazec, int dlzka_r){
for (int j=0; j < dlzka_r - dlzka_v + 1; j++){
for (int i=0; i < dlzka_v; i++) {
if(retazec[j+i] != vzor[i])
break;
}
if (i==dlzka_v) {
return j;
}
}
return -1;
} |
Vizualizácie |
| Príklad 1 |
|
| Príklad 2 |
|
| Priklad 3 |
|
Časová zložitosť |
|
K najhoršiemu prípadu prichádza vtedy, keď o nezhode vzoru a reťazca rozhodne vždy posledný znak vo vzore. Potom urobí algoritmus vždy m–1 (ak m je dĺžka vzoru) porovnaní pre porovnanie rovnosti znakov vzoru a reťazca, a n–m+1 (n je dĺžka reťazca) porovnaní pre porovnanie vzoru od každej možnej a logicky prípustnej začiatočnej pozície v reťazci. Ak má vzor m znakov, nemusí ho algoritmus porovnávať s reťazcom pre také začiatočné pozície, kedy by sa už vzor od začiatočnej pozície po koniec reťazca nezmestil (menej ako m znakov do konca reťazca a žiadne úspešné porovnania). Časová náročnosť je v najhoršom prípade m*n+2*m–n–m2–1, teda rádovo m*n. Priemerný počet porovnaní závisí od veľkosti abecedy použitých znakov a podľa zdroja [7] je odvodený nasledovne: [c/(c-1)]*[1–1/cm]*[n–m+1]+O(1).
|
Porovnanie s predchádzajúcimi algoritmami |
|
Tento algoritmus je tým základným a samozrejme aj najmenej efektívnym. Niekedy je nazývaný brute force, čo odráža skutočnosť, že tento algoritmus nepoužíva na nájdenie vzoru žiadne vylepšenia, ale len "hrubú silu". Ďalšie algoritmy budú opísaný postup riešenia zefektívňovať.
|
| |
| Grafy, tabuľky a porovnanie s predchádzajúcimi algoritmami |
| |
| |
|
