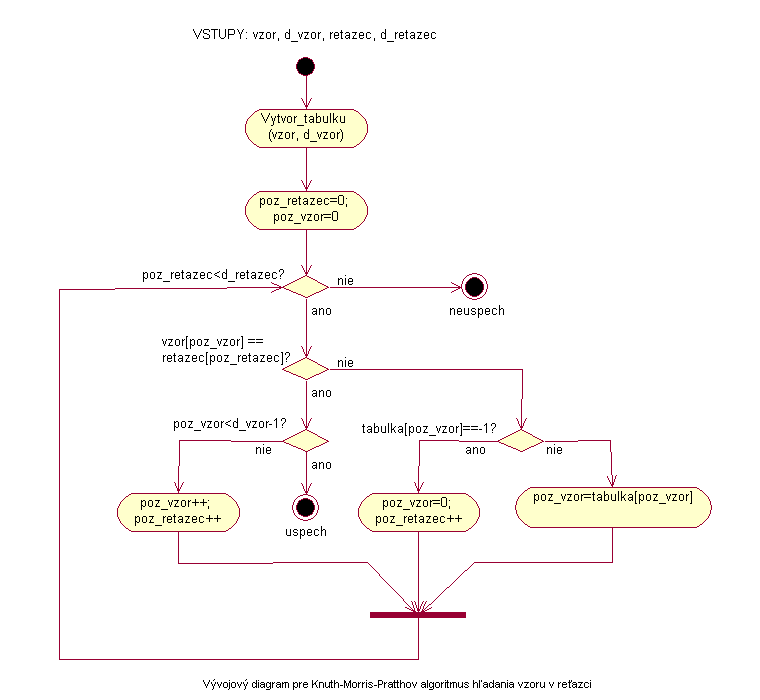
Algoritmus najprv vytvorí tabuľku, v ktorej bude mať zapísané, s ktorým znakom vzoru má porovnať aktuálny znak reťazca pri neúspešnom porovnaní. Táto hodnota sa môže líšiť pre každý znak vzoru. Znamená to, že pri nájdení nezhody nemusí prechádzať už porovnané prvky, ale číslo z tabuľky mu dá informáciu o tom, s ktorým znakom vzoru má tento aktuálny znak reťazca porovnať pred ďalším posunom v reťazci tak, aby zbytočne nemrhal časom a porovnaniami, ktoré vlastne už vykonal. KMP algoritmus podobne ako sekvenčný algoritmus prechádza reťazec od začiatku ku koncu, ale v prípade nezhody pokračuje v porovnaní aktuálneho znaku so znakom vzoru zadaným v tabuľke alebo prejde na znak nasledujúci. Algoritmus porovnáva vzor a reťazec pokiaľ počet zostávajúcich znakov v reťazci je väčší alebo rovný ako potrebný počet úspešných porovnaní pre nájdenie zhody so vzorom.
Príklad tabuľky pre slovo abracadabra
a b r a c a d a b r a
0 1 1 0 2 0 2 0 1 1 0 5
0 – značí, že sa pri nezhode na tejto pozícii môžeme presunúť
na nasledujúci znak reťazca a porovnávať vzor od začiatku
1,2 – značí, že aktuálny znak reťazca, ktorý sa nezhodoval so znakom
vo vzore porovnáme opäť s 1. alebo 2. znakom vo vzore (pri indexovaní od 0 s 0. a 1. znakom)
5 – ak by sme pri nájdení zhody chceli pokračovať ďalej vo vyhľadávaní,
porovnáme aktuálny znak v reťazci s 5. znakom vo vzore (pri indexovaní od 0 so 4. znakom)