|
Information Recommendation Using Context in a Specific Domain Anton Benčič Master thesis project supervised by prof. Mária Bieliková |
Motivation
Information recommendation in its basic form consists of a three step process. The first step is deciding when to recommend some content. Then we have to decide what kind of content should be recommended and in what volume, and finally how to present it to a user. None of these decisions is trivial when we want to perform it in an intelligent way. Most of existing recommenders focus solely on the content part considering others constant which is acceptable, as long as we are dealing with on-demand recommendation. In other words recommendation that takes place after a query of sorts, be it sorting of search results or recommending additional products in a web shop. In these cases we do not have to worry about the time of recommendation as someone else, most often a user, makes the decision.
On the other side in our world of pervasive computing we can see more and more attempts for intelligent proactive recommenders. A proactive recommender is one that engages in the first step of the recommendation process - deciding when a recommendation should happen. This timing decision that is generally based on situation identification often influences all of two three other stages as there is an interdependency link between them. For example the content provided by an intelligent news push service should be different when at a sports match with our friends than the content provided after a movie with our significant other. This goes for content volume and means of presentation as well.
Our main aim is to design and develop a method that is able to efficiently recommend actions based on a user’s situation. We aim for final design that is easily portable among various domains and helps end-user service or application designers to include context awareness with little or no overhead.
Method
With our method we aim at providing means to support autonomous situation-based decision within end-user services or applications. We did not design our method for any specific domain, but we instead designed a method that can be used in various fields. Even though location and time context information are most widely used within context-aware methods and services we still need specific context information in the specific domains to be able to capture all the possibly important parts of the user’s context. For example when designing a context-aware method for news recommendation, important contextual information may be when was the last time the user read some news. On the other hand a movie recommendation method may need to consider what the genre of the last movie was.
The aforementioned examples of domain specificity required us to design our recommendation method in such way that these specifics can be easily captured and incorporated. To achieve that we decided to build our method using symbolic representation for both user’s context (situations) and actions performed by end-user services or applications that define these symbols based on what they need and consider relevant.
Situation Model
Situation model consists of a set of situations that describe the user’s real-life situation and the situation of the environment she is in. Throughout our work we refer to types of situations (i.e. time, location, weather) as to situation classes and to specific situations within them (i.e. morning, home, clear) as to situations. Symbolic situation representation allows for situation models that consist of relatively simple strings (symbols), but allow for representation of a variety of situation classes, from the most simple to complex ones. Each symbol represents a particular situation and consists of two parts. The first part represents the situation class and the second part represents a particular situation within that class. An example may be situation class Weather with value Clear that would be presented as Weather ? Clear. An instance of these situations is what is used to describe the user’s context. We refer to these instances as to situation observations. In addition to their symbolic identification every user-situation observation has three other pieces of information:
- Time – the time at which it was observed
- Certainty – the level of certainty with the observation
- Descend rate – the speed of descending the certainty through time
Action Model
The action model consists of a set of rules that are automatically generated based on the feedback from the end-user service or application and further on the action indicators they identify. An action indicator in any specific domain is anything performed by a user that indicates an appropriate time for a particular action. For example in the domain of news recommendation a strong action indicator for recommending some news is a user actually reading some news. Another indicator may be a user playing a game on her mobile device, because it may indicate that she is possibly free to be presented some interesting news. An action of dismissing a push news notification on the other side can be indicator for not pushing any news. In case of autonomous sound profile switcher an action indicator for turning the sound off is a user actually turning it off.
The actions as well as their indicators are specific to every domain and thus as it is the case with situations, possible actions are represented using symbols and are defined by end-user services or applications. When an end-user service or application observes one of the possible action indicators, it feeds this observation in very much the same way as it does it with situation observations. The action indicator observations fed into our method serve as basis for defining rules. The set of rules that are created in this way for a particular user form her action model.
Evaluation
For evaluation on our method we have implemented a simulation framework and a mobile news recommendation application. The experiment was three-staged. In the first stage we performed a series of simulations to set-up our method’s parameters and ensure that the inner workings are correct and can reliably identify suitable situations for a set of simulated environments and the users within them. In the second stage we distributed our modified mobile application to 6 users to evaluate on the characteristics of situation and feedback data. Our aim here was to verify the preconditions of our simulations to see if the simulated environments and users were representative of those from the real world. In the third stage we took the knowledge from the live experiment in stage two and designed additional simulations that modeled the real environment and user behavior even more closely to their real counterparts.
Base Simulations
The purpose of these simulations is to demonstrate basic and some advanced characteristics of our rule-based action recommendation method. To achieve this we advance from the simplest simulations and scale them up as we progress.
Our most involved experiment simulation besides composed preference tests also our rule retirement model by simulating a user who prefers to read news on Monday morning, but after one and a half month her preferences change to Friday evening (see Figure 1).
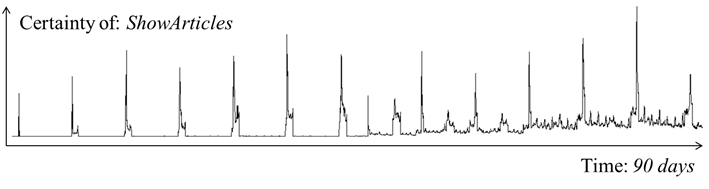
Figure 1. Simulation result.
This experiment spans throughout 90 days and its results clearly demonstrate our method’s capabilities to change when users change their behavior. Throughout the first one and a half month the simulated user gives positive feedback on Monday morning and our method observes and learns this properly as is the case with our fifth simulation. After roughly one and a half month the user’s preferences suddenly change to Friday evening which is represented in the graph by the first spike that is closer to the previous one than the others. The spike right after for Monday morning is around the same size for it has been lowered by lack of feedback on that day, but mainly by addition of new rules for another day for the first time. This lowers the importance of the DayOfWeek situation class. For the rest of the time allotted for the simulation the rules for Monday morning lose their certainty according to the time sensitivity model and the rules for Friday evening are becoming stronger. Because the rules for Monday have little to no influence in the upcoming weeks the importance of the DayOfWeek situation class is raised again as well.
Live Experiment
The base simulations served us to set our method’s parameters and ensure that the underlying mathematical model can correctly identify suitable situation within simulated environments and virtual users. To continue with our experiment and extend both environment and user feedback simulations to even more closely model their real life counterparts we have performed a two-week long live experiment. In this live experiment we have asked six people to install and use our simplified prototype application in their mobile devices (see Figure 2).
Figure 2. Live experiment application.
Their task was to regularly press one of four buttons according to how they felt about reading some interesting news or a similar activity at those times. The specific question the users answered was based on what activity that reminds reading news the user does regularly. For three of the users it was reading news, one had Facebook updates, one had tweets and the last one was answering when a good time for some fun mime drawings was.
Additional Simulations
Based on the characteristics observed in the live experiment we designed a few more simulations that addressed the:
- Situation lock-in
- Weak feedbacks
The situation lock-in is an effect where one situation is always present despite of its non-significance. For example because the live experiment ran through a very short period of time the temperature situations did not fluctuate that much and therefore the class was “locked” in just a few situations for the whole time. Now because all of the rules in such environment have only a few temperature situation observations present in them once the temperature changes the certainty of recommendation for a suitable situation drops. This is however just a short-term problem because as more feedback is received the model accommodates and our method identifies the real importance of the previously locked-in situation classes.
A weak feedback is a feedback that is just weakly supported or not supported at all by additional feedbacks. In other words the collected data contained isolated and scattered random feedbacks in situations such that they were not present in the rest of the time period.
For both of these effects we designed new simulations whose results shown that our method is capable of working even under these real circumstances.
Publications
- Benčič, A.
- Information Recommendation Using Context in a Specific Domain. Master thesis, Slovak University of Technology in Bratislava, May 2012. 62p.
- Benčič, A., Bieliková, M.
- Action Suggestion Using Situation Rules. SMAP 2012. IEEE CS Press. Submitted.
| to Homepage | to Teaching | to the Top |
|
||
|
||