|
Analysis of students answers to questions Michal Hucko Bachelor thesis project supervised by prof. Mária Bieliková |
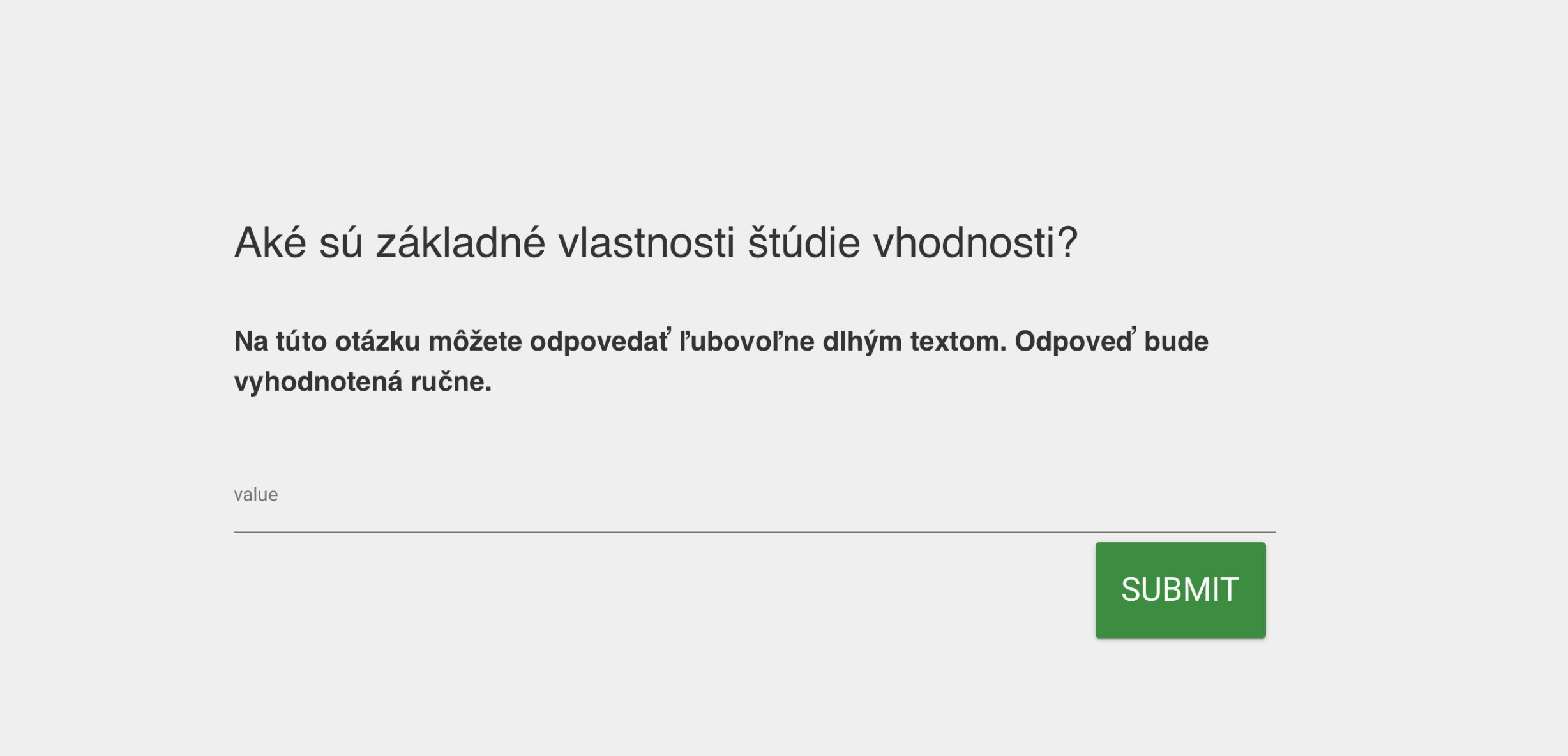
Motivation
Evaluation of the students' answers is a part of the teacher's work. During this process it is crucial to understand them and to be able to compare them. However, this is usually a time consuming task, since the teacher faces a hundreds of records. Even if these records are ordered by the timestamp or alphabetically, there are displayed in a form of an unstructured list, which may also cause trouble while checking them. Moreover, it is difficult to uncover patterns or unusual behaviour.
In our work, we propose a method for structuring the students' answers. This process consists of two main stages. In the first stage, we detect and filter the correct answers, which is achieved with the text classification. The second step is clustering, which results in incorrect answers structuring.
Method
Based on our analysis of students' behaviour in online learning systems, we identified several problems we need to deal with. There, we divided our method into the following steps:
- Acquisition of data from the presentation system. During this process, we need to gather data from the presentation system. These data (in a form of students' answers) is also categorized by the teacher into correct and incorrect ones. Here we may take into account an assumption that certain question tend to repeat from the past courses and can be reused in the following terms.
- Training the text classifier. Labelled answers are an input for the classifier that is intended to predict the correctness of a new (non-labelled) answer of a student.
- Creating answer clusters. Wrong answers obtained from the previous step are grouped into the clusters. Since this step is unsupervised, number of clusters need to be estimated. For this purpose we use affinity propagation.
Evaluation
In our experiments we used data gathered at our university using system ASQ. It is a real time presentation system which provides interactie presentations. Students can connect to them with their smart-phones or laptops. In the system we prepared set of tests for students.
For classification we used dataset gathered from the course Principles of software engineering. It consisted of 28 open questions with 1680 labeled answers. Labels mark whether the answer is correct or not, their were made by teachers. Students answered questions at school in limited time using computers. They received points for inputting the correct answers.
Second dataset was gathered at lectures of Principles of software engineering as well, but here the system ASQ was also utilized. Students were also motivated with extra points. For every lecture more than 100 active students were present. Except computers they used their smart-phones to connect. We had 8 presentations on course with more than 40 questions in total. We used questions from the first dataset. For the experiment we chose only those with shorter answers (3 words in average) for the experiment. Dataset consist of totally 9 questions with more than 600 answers.
Classification of labeled data reached f1-micro score more than 90% using SVM. In the clustering we reached results comparable with estimations of experts.
Publications
- M. Hucko.
- Analysis of students answers to questions.
Bachelor thesis, Slovak University of Technology in Bratislava 2017.
46p.
 pdf (in Slovak)
pdf (in Slovak)
- V. Triglianos, M. Labaj, R. Moro, J. Simko, M. Hucko, J. Tvarozek, C. Pautasso, M. Bielikova.
 Experiences Using an Interactive Presentation Platform in a Functional and Logic Programming Course.
Experiences Using an Interactive Presentation Platform in a Functional and Logic Programming Course.
In Adjunct Proc. of UMAP '17, the 25th Conference on User Modeling, Adaptation and Personalization, ACM, 311-316.
to Homepage to Teaching 
to the Top
|
||
|
||