|
TitleR - Personalized recommendation of interesting texts Michal Kompan Master thesis project supervised by prof. Mária Bieliková |
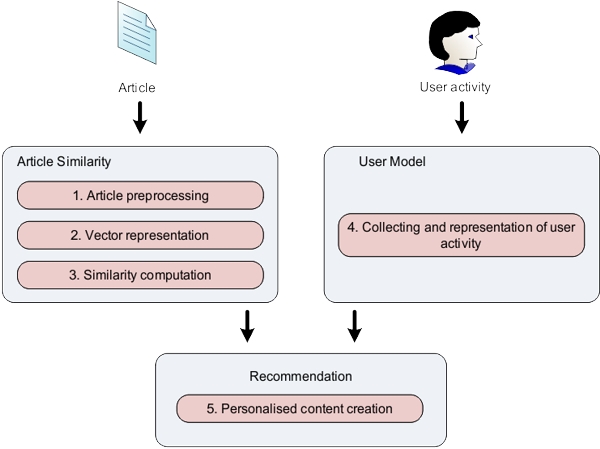
Motivation
The data amount on the web is serious problem for the common user. The existence of information is not so relevant, when there is no one who can access or find this information in acceptable time. Our method for similarity computation compresses article information value to short vectors, which are used for fast similarity computation over the specific articles time-window. This vector represents article in an effective way, so there is no need to store whole articles. Proposed method expects pre-processed article as an input and produces vector representation usually no longer than 30 words. Then these vectors can be easily used for similarity computations or we can use them in special structures for recommendation.
Method - Recommendation
The input for recommendation method represents two lists:
We need clearly to identify users and articles they read. There is need to distinguish between before not recommended and recommended articles. The first step of proposed recommendation method is to define number of articles to recommend. Based on this is list of recommended articles constructed from two sub lists:
The ratio for these lists is dynamically computed.
Evaluation
The verification of the recommendation method is based on synthetic tests. The dataset – 3 days of user activity logs from news portal SME.SK was divided into train and test period. We created recommendation list based on train period, then was the recommendation compared to real user activity from test period. This comparison was done for combination of section and category and for articles respectively.
Publications
- Kompan, M.
- Personalized recommendation of interesting texts. Master thesis, Slovak University of Technology in Bratislava 2010. 55p.
 pdf (in Slovak)
pdf (in Slovak)
- Kompan, M.
- News Representation for Effective Similarity Search. In Proc. of Informatics and Information Technology Student Research Conference IIT.SRC 2010, pp. 177-184.
- M. Kompan, M. Bieliková.
- Content-based News Recommendation. In E-Commerce and Web Technologies, Lecture Notes in Business Information Processing, Vol. 61, Part 2, Springer, pp.61-72.
| to Homepage | to Teaching | to the Top |
|
||
|
||