|
Automatic Photo Annotation based on Visual Content Analysis Eduard Kuric Master thesis project supervised by prof. Mária Bieliková |
Motivation
Each of us likely has hundreds to thousands photos and each of us has probably once thought “I would like to show you the photo, but I am unable to find it”. With the expansion and increasing popularity of digital and mobile phone cameras, we need to search images effectively and exactly more than ever before. Focusing on visual query forms, many content-based image retrieval (CBIR) methods and techniques have been proposed in recent years, but they have several drawbacks. On the one hand, for methods based on query by example, a query image is often absent. On the other hand, query by sketch approaches are too complex for common users and a visual content interpretation of a user image concept is difficult. Therefore, image search using keywords is presently the most widely used approach.
Content based indexing of images is more difficult than for textual documents because they do not contain units like words. Image search is based on using annotations and semantic tags that are associated with images. However, annotations are entered by users and their manual creation for a large quantity of images is very time-consuming with often subjective results. Therefore, for more than a decade, automatic image annotation has been a most challenging task.
Method
Automatic image annotation methods require a quality training image dataset, from which annotations for target images are obtained. At present, the main problem with these methods is their low effectiveness and scalability if a large-scale training dataset is used. Current methods use only global image features for search.
- We proposed a method to obtain annotations for target images, which is based on a novel combination of local and global features during search stage. We are able to ensure the robustness and generalization needed by complex queries and significantly eliminate irrelevant results. In our method, in analogy with text documents, the global features represent words extracted from paragraphs of a document with the highest frequency of occurrence and the local features represent key words extracted from the entire document. We are able to identify objects directly in target images and for each obtained annotation we estimate the probability of its relevance.
- During search, we retrieve similar images containing the correct keywords for a given target image. For example, we prioritize images where extracted objects of interest from the target images are dominant as it is more likely that words associated with the images describe the objects.
- We place great emphasis on performance and have thus tailored our method to use large-scale image training datasets. To cope with the huge number of extracted features, we have designed disk-based sensitive hashing for indexing and clustering descriptors.
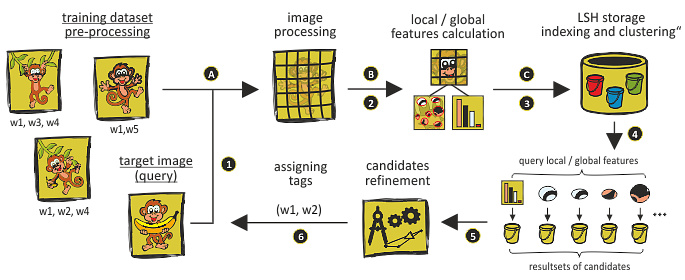 Scheme of our method for automatic image annotation.
Scheme of our method for automatic image annotation.
Evaluation
Our evaluation was conducted over the Corel5K corpus. It consists of 5,000 images from 50 Corel Stock Photo CDs and each CD includes 100 images with the same theme. The corpus is used widely in the automatic image annotation area and includes a variety of subjects, ranging from urban to nature scenes and from artificial objects to animals. It is divided into 2 sets: a training set of 4,500 photos and a test set of 500 photos. Each photo is associated with 1-5 keywords and all photos are in the resolution 384x256 pixels and 256x384 pixels, respectively.
We compare our method with the Translation Model. To evaluate the annotation performance, we use the precision (P) and recall (R) metrics. Let A be the number of images automatically annotated with a given word, B the number of images correctly annotated with that word. C is the number of images having that word in ground-truth annotation.
 |
Human annotation:
Automatic annotation: |
 |
Human annotation:
Automatic annotation: |
Publications
- Kuric, E.
- Automatic Photo Annotation based on Visual Content Analysis. Master thesis, Slovak University of Technology in Bratislava, May 2011. 37p.
 pdf (in Slovak)
pdf (in Slovak)
- Kuric, E., Bieliková, M.
- Automatic image annotation using global and local features. In Proc. of SMAP 2011: 6th International Workshop on Semantic media adaptation and personalization, Vigo (Spain), IEEE Press.
- Kuric, E.
- Automatic Photo Annotation Based on Visual Content Analysis. In Bieliková, M. Student Research Conference 2011, Vol. 1: 7th Student Research Conference in Informatics and Information Technologies Bratislava, Slovakia, May 4, 2011, pp.57-62.
| to Homepage | to Teaching | to the Top |
|
||
|
||