|
Recommendation and Collaboration Martin Labaj Master thesis project supervised by prof. Mária Bieliková |
Motivation
In current adaptive Web systems, we are very interested in user actions — e.g. we can exploit existing users' ratings in recommendation to users who have not yet rated some items or we can track how users work with our Web system or resources presented in such system. These user actions are known as user feedback and there are two main categories: explicit feedback and implicit feedback. In explicit user feedback, users knowingly provide ratings for items — they may show interest by selecting a number of stars or by selecting plus or minus button. In implicit user feedback, we track ordinary users' actions — if user buys an item, he is interested in it; the longer he take reading some content, the more important it may be for him.
Within Web documents we may benefit from finer interest resolution than on the level of entire objects (documents). When we track interest for document fragments, we can summarize documents, provide quick overview for revisitation, etc. However obtaining user feedback for fragments is problematic. We cannot ask users to rate each paragraph of text document. When we try to track how much time has been each individual fragment displayed for a user, we cannot differentiate whether user left the computer or he was actually reading it without moving a mouse, etc. Also when entire document fits on single screen, all parts are displayed for the same time. To solve both problems we need to physically track user's gaze.
Method
We divided two main parts of a Web application (the application itself and current document being presented) into several nested levels of fragments. We track various implicit interest indicators and map them to these fragments. We divided available indicators into four groups: untargeted, passively targeted, actively targeted and document based. Indicators are untargeted/targeted based on whether user performs this action in relation to observed fragment. By targeting actively/passively we mean whether user for example actively copies a part of text or the text is only passively displayed on screen. We set weights for the groups and for indicators within each group experimentally and by evaluation of previously gathered logs of user actions. Our most important indicator is user gaze. Also, by the means of gaze tracking we detect when the user is giving attention to current Web application and when he is working with other applications or even left the computer.
We then use collected feedback mapped to fragments in the following scenarios:
- Interesting fragments — identified interesting fragments are highlighted. User can aim at the parts of document that were important to other users. When revisiting, he can also quickly see what attention has he paid to which parts. Summarization, etc. is performed in the same fashion.
- Adaptive guide/explicit feedback collection — we adaptively display hints, tutorials, etc. based on users actions regarding related application or document fragments. In the same way we adaptively collect explicit feedback when we ask user to provide rating, explanation of his current activity, etc. Traditionally we only know that user has not yet clicked any of the recommended items. In our approach we know that the user was actually looking at the recommendation list, but then chose an item from a menu instead. Right then we can ask him why he did so and obtain valuable feedback for recommender evaluation.
Evaluation
We evaluated our method in the domain of adaptive learning system in an instance of Adaptive LEarning Framework (ALEF). Since professional gaze tracking is very expensive and requires custom hardware, while audience of a typical Web application is wide and posses only common webcam at the most, we implemented our method as an browser extension using ordinary webcam gaze tracking. Part of our evaluation was to see whether the gaze tracking can be brought to home users with no supervisor, therefore effort was made to make the installation and usage of the extension (including gaze tracking setup) as easy to perform as possible.
We performed live experiment with 34 undergraduate students studying in the ALEF system for an exam. We provided them with only brief instructions on how to install the extension and they worked unsupervised in their home environment. 10 students used various models of standalone webcams and 12 used webcams built-in in their laptops. During two weeks we collected interest indicators for document fragments and users also had a task to highlight parts they considered important. Meanwhile we displayed adaptive questions. When considering importance of document fragments, we compared our method with included user gaze with simplified approach without gaze and also with manual highlights from users (explicit feedback). With adaptive questions, we traced accuracy (whether the user was really working with application fragments we identified) and also how users treated hints/questions when they were shown at random and when they were shown based on their activity (mouse and gaze tracking separately).
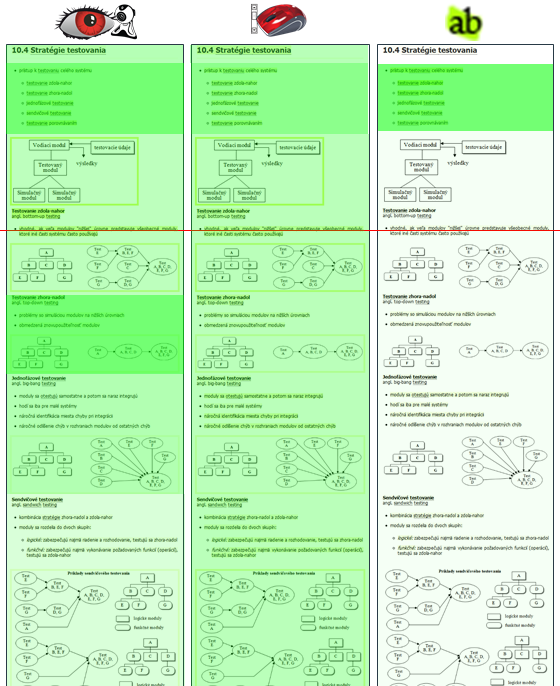
Fragment importance in a learning content based on (left to right): our method with gaze tracking, our
method without gaze tracking (mostly read wear), manual highlights from users. (Red line marks page fold.)
Publications
- Labaj, M.
- Recommendation and Collaboration Based on Implicit Feedback. Master thesis, Slovak University of Technology
in Bratislava
2011. 57p.
 pdf (in Slovak)
pdf (in Slovak)
- Bieliková, M., Šimko, M., Barla, M., Chudá, D., Michlík, P., Labaj, M., Mihál, V., Unčík, M.
- ALEF: Web 2.0 Principles in Learning and Collaboration. In e-Learning'10, Proceedings of the International Conference on e-Learning and the Knowledge Society, 2010, p. 54–59.
- Labaj, M.
- Recommendation and Collaboration Based on Implicit Feedback in Web-Based Learning. In Proc. of Student Research conference - IIT.SRC 2011, M. Bieliková (Ed.), Bratislava, Slovakia, 2011, pp.63-68.
| to Homepage | to Teaching | to the Top |
|
||
|
||