|
Researcher Modeling in Personalized Digital Library Martin Lipták Master thesis project supervised by prof. Mária Bieliková |
Motivation
Digital libraries are an important resource for all researchers regardless of their field of study. They are used to publish, search and access research works. Researchers can find solutions for particular problems, follow the latest trends in domains of their interest or publish results of their work. The amount of information in every domain has grown exponentially recently and still continues to grow at an increasing rate. Digital libraries are no exception to this trend with rapid growth of number of published works. This has two serious consequences. Firstly, researchers miss many works that would be useful to their interests. Secondly, they spend large amount of time reading works that turn out inapplicable to their research. These issues are generally solved with personalization, which besides tackling information overload, enhances user experience of digital library applications. Personalized digital library applications adapt their interfaces and contents based on the current user in order to provide a better service for each individual user. We design and evaluate a flexible and extensible user model for digital libraries.
Researcher Model Design
We intend to make the design general to make it realizable in any digital library system. We have set the following requirements.
- Accuracy. Every model is an estimation of what is being modeled. The researcher model reflects the researcher's interests in digital library. The estimations should be as accurate as possible. However, as we deal with models and estimations, we do not strictly require them to reflect the researcher's interests exactly. It is not even possible, because there is no way to know exact interests of the user. We propose a general researcher model, which is close to the researcher's interests and can be utilized to personalize multiple user features in a digital library application.
- Flexibility. Digital library applications provide many user features and the researcher's interactions with these user features can be logged. Domain models in digital libraries contain diverse document metadata, which are many times enriched by external services or other digital libraries. Also distinct user features have different requirements on the researcher model. The researcher model takes advantage of all the sources of user and domain data and responds to the requirements of different user features in digital libraries.
- Extensibility. New user features or data sources can be added to a digital library application. Also new user features can be added to the application and thus new requirements on the researcher model are made. The researcher model can be extended to respond to these changes.
We propose an overlaying user model with vector-based representation of researcher's interests. Every researcher has her own vector with weights of all the interests in the digital library. Representation of interests depends on the particular realization of the design --- keywords, terms or concepts can be used. There are multiple researcher model types, since every user feature in digital library applications might require a different model.
The researcher model is internally represented as a graph of all the relevant relations and entities in an information system (e.g. users, documents, tags, extracted keywords). These relations have weights, which denote their strength. Relevant relations and entities are copied from the original data model in the information system (e.g. extracted keyword weight for a document, number of times the user has accessed a document). New entities and relations are created from the existing relations in the graph model in four ways.
- Combination. New relations are created by combining a matrix of existing relations. Weights of all the combined relations are simply either summed or multiplied. The relations that are placed one after another are multiplied (one relation weights the importance of the other - they are put into intersection) and the results are summed (two relations are parallel - they are put into union). Coefficients are utilized to weight the summands.
- Normalization. New entities are created by applying a normalization function to existing entities. New relations connecting the original entities with the new entities are created --- there are one-to-one connections between the original entities and the new entities.
- Extraction. New entities are created by applying an extraction function to existing entities. New relations connecting an original entity with one or more new entities are created --- there are one-to-many connections between the original entities and the new entities.
- Joining. A new relation is created by joining two similar entities. There is an one-to-one connection between existing entities.
The entities and relations of the model are created in the determined order, as they can be dependent one on the other.
There are two principal entities in the researcher model - Researcher and Interest. All the other entities in the digital library are set between them. Researcher is connected to content entities with a has relation, which indicates the researcher's interest in them. Content entities are further connected to the Interest entity with a contains relation, which indicates importance of the interest for describing the content entity. The relation between Researcher and Interest depends on all the other relations between them. The weights of this relation can be conceptually considered the researcher model represented as a vector of researcher's interests.
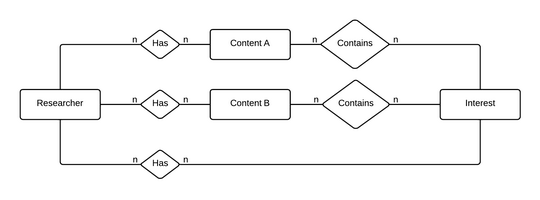
Each digital library system provides different set of content entities. We list a few examples to make clear what content entities are.
- Document. Digital libraries store documents. Researchers have various relations with documents - researchers save them to their personal libraries, researchers are their authors or researchers read them. The has relation between Researcher and Document combines all these relations to estimate the overall researcher-document relation. Documents have been tagged, categorized to folders, annotated, they have their authors, categorization keywords and other metadata. We have listed other entities, which are related to documents. These entities are further normalized or extracted to relate them with interests. The contains relation combines all the relations between documents and interests and estimates the document-interest relation.
- Tag.Researchers tag documents or use tags for navigation in the digital library. The has relation between Researcher and Tag combines these relations to estimate the overall researcher-tag relation. The contains relation normalizes tags to interests or combines multiple relations if a more complex transformation of tags to interests is needed. Researchers also categorize documents to folders, this can be treated in a similar way as tags.
- Annotation.Researchers annotate documents in digital libraries. The has relation between Researcher and Annotation indicates that a researcher has created an annotation. The contains relation extracts interests from annotations.
- Query.Researchers search in digital libraries. Search queries can be considered content entities as well. The has relation between Researcher and Query indicates that a researcher has used a query. The contains relation extracts interests from search queries.
The has relation between Researcher and Interest combines all the mentioned relations and strengthens the weights of the individual interests depending on the activity of every researcher in the digital library system.
Evaluation
We realize the designed researcher model in the Annota digital library. Annota takes advantage of Mendeley API, ACM DL metadata and extracts additional keywords using AlchemyAPI. It collects logs about user's activity in Annota web application and on the ACM web pages. Annota provides necessary data and access to the user feedback.
We evaluate accuracy of the researcher model by investigating how the researcher perceives her own researcher model terms. We verify if terms in the researcher model are related to the interests of the researcher. We compare the level of importance of particular terms assigned by the researchers with the importance of the terms resulted form the research model. We have set two hypotheses.
- Researchers identify terms in their researcher models as their interests.
- The order of the terms in the researcher model correlates with the importance of the terms to the researcher.
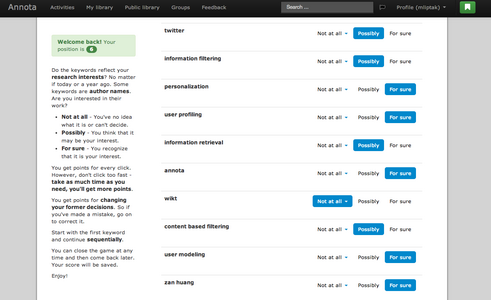
We have performed two quantitative experiments, where users of Annota evaluated terms from their researcher models. After the experiments, we asked the users for their opinion on the terms they had been evaluating to bring qualitative insights into the evaluation.
The participants were presented a list of terms. They were asked, if the terms reflected their research interests. They chose one of three answers - Not at all, Possibly and For sure. The best average evaluation in terms group was 0.82, which means that the terms in the first 20 terms had been mostly selected as For sure. All of the participants stated that the number of terms related to their interests was decreasing as they were advancing in the researcher model game. The correlation between the position of the terms in the researcher model and their average evaluation ranges from -0.83 - -0.97.
Conclusions
We have proposed a researcher model that comprises all types of user and domain data available in digital libraries. All the researcher's interactions along with all relevant content metadata are extracted from the digital library data model to graph relations. Every relation has a weight denoting its strength. Higher-level relations are deduced from the extracted relations and their weight is computed as a linear function of the original relations. The final relation is a representation of the researcher's interests in the digital library. Exact composition of relations and entities inside the graph and the coefficients used in the linear functions can be adjusted for the requirements of each digital library.
The researcher model is a vector of terms from outside, but a graph inside, whereby the components of the model are reusable and the model is flexible and extensible. We evaluated the accuracy of the researcher model by investigating how researchers themselves perceive their researcher model terms. We performed two experiments. Both experiments confirmed that researchers identify terms in their researcher models as their interests and the order of the terms in the researcher model correlates with the importance of the terms to the researcher.
Besides reaching the objectives of the work by designing a general user model for digital libraries, we have created a base for more research in the domain of digital libraries. The researcher model realized in Annota is extensible and can be used to implement and compare various user modeling and information retrieval techniques. We hope that our effort grounds further research in digital libraries.
Publications
- Martin, L.
- Researcher Modeling in Personalized Digital Library. Master thesis, Slovak University of Technology in Bratislava, May 2014. 61p.
 pdf
pdf
| to Homepage | to Teaching | to the Top |
|
||
|
||