|
Personalized Text Summarization Róbert Móro Master thesis project supervised by prof. Mária Bieliková |
Motivation
Information overload is one of the most serious problems of the present-day Web. There are various approaches addressing this problem; we are interested mainly in two: automatic text summarization and personalization.
Automatic text summarization aims to extract the most important information from the document, which can help readers (users) to decide whether it is relevant for them and they should read the whole text or not. However, conventional (generic) summarization methods summarize the content of the document without considering the differences in users, their needs or characteristics. Personalized summarization, on the other hand, uses this additional information about users’ characteristics to produce summaries more suitable for a particular user’s needs.
Therefore, we have focused on two open problems: what information can be used to personalize summaries and secondly, how to combine different sources of personalization.
Method
We have proposed a method of personalized text summarization based on a method of latent semantic analysis which consists of the following steps:
- Pre-processing
- Construction of a personalized terms-sentences matrix
- Singular value decomposition (SVD)
- Sentences selection
We have identified the construction of a terms-sentences matrix representing the document as a step suitable for personalization of the summarization. We have extended the conventional weighting scheme based on tf-idf method by linear combination of multiple raters, which positively or negatively affect the weight of each term.
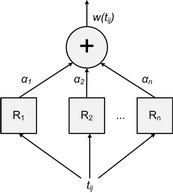
Term weighing by combination of raters.
We have designed a set of generic and personalized raters focusing on three main sources of personalization:
- Domain conceptualization in the form of the relevant domain terms (RDT rater)
- Knowledge of the users (Knowledge rater)
- Annotations added by users, i.e. highlights or tags (Annotations rater)
Our method is domain- and language-independent. However, we have focused on the domain of learning and the specific scenario of summarization for knowledge revision during evaluation. In this scenario, we have to consider other aspects as well, such as the time of revision and the way of selecting the documents to revise from. That is why we have also proposed a personalized method of selecting the documents for revision which takes into account various characteristics, e.g. recent changes of a student’s knowledge supporting concepts, the knowledge of which the user has recently gained or, on the contrary, lost.
The idea is that if a knowledge of a concept had increased during the session, the user has learned something new and she should revise it before starting learning in the next session. Similarly, if the knowledge had decreased, the user forgot what she had known before (or our estimation in the user model had been wrong) and therefore, she should revise the concept to regain the forgotten knowledge. If a knowledge of a concept had not changed, we do not need to revise it.
Evaluation
We have evaluated our proposed method of personalized summarization in the domain of learning by means of a standalone summarizer integrated with the educational system ALEF. We have performed two experiments during Functional and Logic Programming (FLP) and Principles of Software Engineering (PSE) courses.
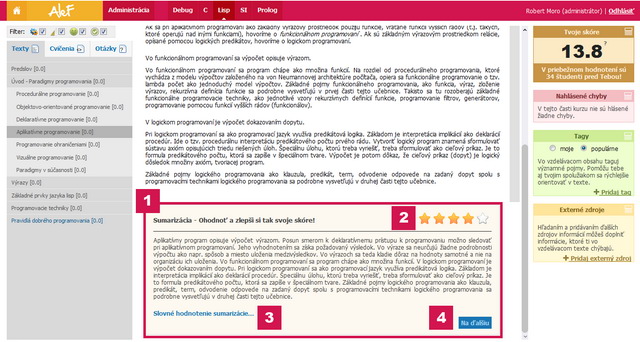
Example screenshot of ALEF (in Slovak) with the integrated summarizer (1). Current user rating is shown in the right top corner (2). Students can also add feedback in the form of free text (3) or navigate themselves to the next summary by clicking the Next button in the right bottom corner (4).
In total, 75 students have participated on these experiments. Their task has been to evaluate quality of the presented summaries of educational texts by rating them and providing feedback in the form of answers to the follow-up questions. We have incquired whether whether the sentences selected for the summary are representative, whether the summary is suitable for the revision or whether it could help them to decide the document relevance. We have also been interested whether the length of the summary is suitable given the length and content of the document and if it is readable and comprehensible.
Furthermore, we have chosen a control expert group to compare their summary evaluation to that of the other students. The group has consisted of five to seven domain experts. In contrast to the other participants, they have been presented both summary variants (in random order) for each educational text in order to decide which variant is better or whether they are equal.
We have gathered summaries for 303 educational texts (explanation learning objects), 2242 summary ratings and 385 summary variants comparisons from experts. Moreover, students have answered 479 follow-up questions. Our experimental results suggest that using the domain-relevant terms in the process of summarization, as well as annotations, can help selecting representative sentences capable of summarizing the document, even for revision. Furthermore, students' answers to the follow-up questions show that our approach is capable of generating readable and comprehensible summaries with satisfiable length.
Publications
- Móro, R.
- Personalized Text Summarization. Master thesis, Slovak University of Technology in Bratislava, May 2012. 64p.
 pdf (in Slovak)
pdf (in Slovak)
- Móro, R., Bieliková, M.
- Personalized Text Summarization Based on Important Terms Identification. In Proceedings 23rd Int. Conf. on Database and Expert Systems Application (Workshop on Text-based Information Retrieval), DEXA 2012. IEEE CS Press, September 2012 [to appear].
- Móro, R., Srba, I., Unčík, M., Šimko, M., Bieliková, M.
- Towards Collaborative Metadata Enrichment for Adaptive Web-Based Learning. In Proceedings of the 2011 IEEE/WIC/ACM Int. Conf. on Web Intelligence and Intelligent Agent Technology, WI-IAT 2011. IEEE CS Press, August 2011, pp.106-109.
- Móro, R.
- Combinations of Different Raters for Text Summarization. Information Sciences and Technologies Bulletin of the ACM Slovakia, Vol. 4, No. 2 (2012) 56-58.
| to Homepage | to Teaching | to the Top |
|
||
|
||