|
Navigation on the Web Using Annotations Jakub Ševcech Master thesis project supervised by prof. Mária Bieliková |
Motivation
We often use various services for creating bookmarks, tags, highlights and other types of annotations while surfing the Web or just reading electronic documents. Many services such as Diigo or Mendeley are using these annotations to support navigation in user's collection of documents. They allow users to organize documents via tags and help in search for documents in collection. All of these applications provide user with motivation, that someday in the future, he can use annotations to find once read document or search for documents using annotations once there will be enough annotated documents. There is however missing motivation that will reward user in time of annotation creation. To provide instantaneous reward for creating annotations into documents we proposed a method for query construction from currently studied document and attached annotations. The query is created in time user is reading documents and can be used to search for further documents related to the current document.
Method
Commonly used search engines such as ElasticSearch or Apache Solr provide special type of query interface called “more like this” query, which processes source text and returns list of similar documents. Internally, the search engine extracts the most important words using tf-idf metric from source text and uses these words as a query to search for related documents. We believe that not only term frequency is important for query word extraction. Especially if we suppose that while reading the document, users are most interested in only a portion of the document, the portion where they attach annotations. To take into account both term frequency and text structure, we proposed a method for query construction based on text to graph transformation and query extraction using spreading activation.
Text to graph transformation
The text to graph transformation is based on word neighbourhood in the text. The graph created from text using words neighbourhood conserves words importance in node degree but it also reflects the structure of the source text in the structure of edges. We use this graph to extract words that can form queries to retrieve similar documents using spreading activation algorithm.
Query word extraction
In the text transformed to graph we can use spreading activation algorithm to find the most important nodes/words. Using this algorithm the initial activation is propagating through the graph and we observe where this activation is concentrating. In our case the activation is inserted into the graph through annotations attached to the document by its reader. We can divide attached annotations into two classes:
- that highlight parts of documents and
- that attach additional content into documents.
Those, which highlight parts of the document, contribute by activation to nodes representing words of highlighted part of the document. Annotations that enrich content of the document are extending the document graph by adding new nodes and edges and inserting activation to this extended part of the graph. When initial activation is spreading through created graph, the nodes where activation is concentrating are considered words fit into the query.
Implementation of a service for inserting annotations into web pages
For the purpose of annotation collection and for studying behavior of users while annotating documents we have developed a service called Annota, which allows users to attach annotations to web pages and to PDF documents displayed in a web browser via Firefox extension. The user can create various types of annotations such as: tags, highlights, comments attached to text selections and notes attached to the document as a whole. The service is focused on supporting visitors of digital libraries by the possibility to insert annotations into web pages and research articles in digital libraries, by bookmarking and sharing documents and annotations in groups.
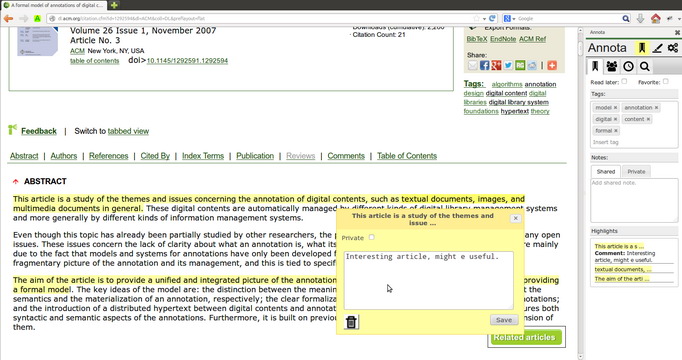
Evaluation
To evaluate proposed method we analyzed properties of annotations created by users of Annota. We used derived annotation properties to simulate annotations attached into dataset extracted from Wikipedia. The final evaluation we realized using user study among users of Annota.
We analyzed behavior of users while annotating documents using Annota. During 4 months time period 82 users created 1416 bookmarks and 399 in-text annotations. We studied multiple parameters of created annotations and notes and we derived probabilistic distributions of these parameters. We studied properties such as note length, number of highlights per user and per document, highlighted text length or probability of comment to be attached to highlighted text.
Simulation
We performed a simulation, to find optimal weights for various types of annotations and number of iterations of proposed method for query construction from document text and attached annotations. We used this simulation to compare proposed method with tf-idf based method used by ElasticSearch.
To create dataset we performed simulation on, we used disambiguation pages from Wikipedia. We used pages disambiguation page was linking to to create documents with syntactically similar sections simulating sections of single document describing multiple topics. In the simulation we generated annotations in a way to correspond with probabilistic distributions extracted from annotations created by users of Annota and we attached them to sections of created documents. We used document content and attached annotations to create queries for similar document retrieval. We used these queries to search among all downloaded Wikipedia pages for relevant pages using ElasticSearch. We considered page to be relevant if it had common category with page, annotated section was extracted from. We compared proposed method and tf-idf based method in three experiments: without using annotations, using generated annotations and with whole abstract annotated. Results are summarized in the following table.
Table 1. Results of comparison of proposed method with tf-idf based method
| Method | Precision |
| Tf-idf based with no annotations | 21.32% |
| Proposed with no annotations | 21.96% |
| Tf-idf based with generated annotations | 33.64% |
| Proposed with generated annotations | 37.07% |
| Tf-idf based with whole fragment annotated | 43.20% |
| Proposed with whole fragment annotated | 53.34% |
Proposed method provides significantly higher precision in query construction for related document retrieval compared to tf-idf based method when generated annotations were used in query construction process and when whole document fragments were used.
User study
We interviewed multiple users of Annota about their habits while annotating documents. When annotating electronic documents, they are using various tools to create bookmarks, to-do lists, to save documents for later, to insert highlights, comments and other types of annotations into documents. The most frequently used types of annotations are tags and in-text highlights. The purpose for creating annotations such as notes, comments and highlights is to summarize studied documents, describe documents, highlight most important sections, to store their thoughts about studied documents and as a form of in-document navigation to support fast recollection of document when returning to previously studied document. In this study interviewed volunteers confirmed our assumption that via annotations users are indicating those parts of the document they are most interested in.
Publications
- Ševcech, J.
- Navigation on the web using annotations. Master thesis, Slovak University of Technology in Bratislava, May 2013. 63p.
 pdf (in Slovak)
pdf (in Slovak)
- Ševcech, J., Bieliková, M., Burger, R., Barla, M.
- Logging activity of researchers in digital library enhanced by annotations. In 7th Workshop on Intelligent and Knowledge oriented Technologies, 2012, pp. 197-200. (in Slovak)
- Ševcech, J., Bieliková, M.
- Related Documents Search Based on User Created Annotations. In Proc. of ASIR 2013 (FedCSIS). IEEE Computer Society. Accepted.
| to Homepage | to Teaching | to the Top |
|
||
|
||