|
Modelling the appropriateness of text posts Andrej Švec Master thesis project supervised by prof. Mária Bieliková and Matúš Pikuliak |
Motivation
Today’s situation on the Web is characteristic by growth of the amount of user generated content. Social networks, discussion platforms and blogs are in expansion. However there are also negative aspects emerging with the possibility of expressing one’s opinion publicly on the Web. The users may start to insult or offend other users or groups of users.
Maintaining the discussion in bounds of politeness and respect to other users is a difficult task usually entrusted to moderators. However the amount of user generated content grows every year and so the moderators do not manage to read all the comments. This results in closing of the discussions or discussions full of inappropriate posts.
For this reason, automated tools are being applied in this field. Their goal is to simplify and accelerate moderator’s work. These tools are often based on machine learning.
Method
We proposed a method for accelerating moderator’s work based on artificial neural networks. The method consists of following steps:
- Firstly, we detect potentially inappropriate comments in order to show them to the moderators so that they can address these comments as soon as possible.
- Secondly, we highlight inappropriate parts in these comments so that the moderators can scan through the content of a comment faster.
Detecting inappropriate comments
We treat this problem as a binary classification into classes appropriate / inappropriate. The model takes as input word embeddings of a comment and outputs the probability distribution over individual classes. Comments are then ordered by the descending probability of being inappropriate, which means the most inappropriate comments will reach the moderator as first.
For this task we use a stacked bidirectional recurrent neural network classifier. We did a hyperparamter grid search of following hyperparameters: recurrent unit type (LSTM, RCNN), depth (2, 3), hidden layer size (200, 300, 500) and in case of RCNN also kernel size (2, 4). Finally we achieved the best results with a bidirectional 2-layer RCNN with kernel size 2 and hidden layer size 300.
Highlighting inappropriate parts
The model for highlighting inappropriate parts in inappropriate comments consists of two neural networks trained jointly. First network, generator, tries to select inappropriate words from an inappropriate comment. These selected words are then classified by second network, classifier.
The generator is trained using reinforcement learning and gets rewards and costs from classifier. The training is based on assumption that the selected words are responsible for the comment being inappropriate if the classifier is able to classify the comment correctly by only using words selected by generator. This way we could train the model without need for word-level inappropriateness annotations in the data.
Both generator and classifier are realised as 2-layer RCNN with hidden layer size 300 and kernel size 2.
Evaluation
We trained and evaluated our models on a proprietary dataset containing 20 million comments in Slovak language. Human moderators have been reviewing reported comments and removing them if they were inappropriate for several years. We used these removals as annotations for training and evaluation of the performance.
Detecting inappropriate comments
In order to measure the performance of the model for detection of inappropriate comments, we extracted a balanced test dataset of 20 000 comments from the newest data, so that we knew how well the model performs on today’s comments.
We compared individual models using standard metrics: accuracy, F1-score, AUC and average precision, which is a metric taking into account the ordering of the comments in the list shown to the moderators. Our best model achieved an accuracy of 79.4 %, F1-score of 0,793, AUC of 0.872 and average precision of 0,861. Results and comparison with baseline models can be seen in Figure 1.
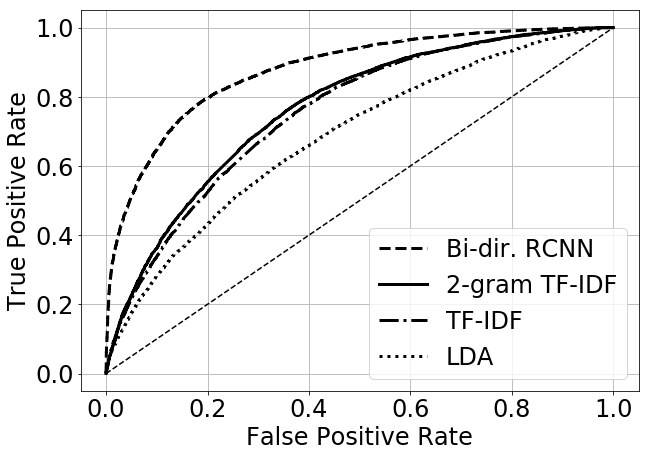
Figure 1. Comparison of ROCs of our model and baseline models. These were based on text features which were then classified by Boosted decision trees.
The results of the model were very satisfactory also for human moderators from one of the largest Slovak news and discussion platforms and thus the model is being actively used in real world use case as a support tool for the moderators.
Highlighting inappropriate parts
We evaluated the quality of selected inappropriate parts on a manually annotated dataset of 100 comments comprising ~ 3 600 word-level annotations. We evaluated the quality of highlights based on two metrics: precision and length of highlights. The model achieved a high precision of 88.5 %. These results were achieved when the model was highlighting 11.4 % of words from original comment.
We compared the model with a model based on first-derivative salience. The comparison of these two models is shown in Figure 2.
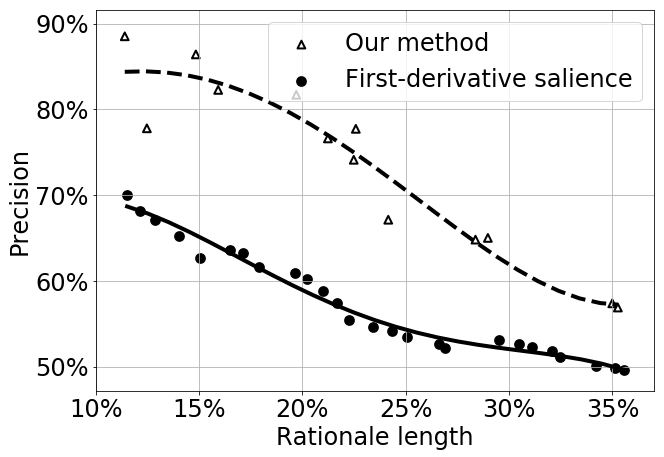
Figure 2. Comparison of performance of our method with the method of first-derivative salience in the task of highlighting inappropriate parts of comments.
Publications
- Švec, A.; Pikuliak, M.; Šimko, M.; Bieliková, M.
- Improving Moderation of Online Discussions via Interpretable Neural Models. In Proceedings of the Second Workshop on Abusive Language Online. Association for Computational Linguistics, 2018.
 pdf
pdf
| to Homepage | to Teaching | to the Top |
|
||
|
||