|
Adaptive Navigation Support in Open Spaces Marek Tomša Master thesis project supervised by prof. Mária Bieliková |
Motivation
The problem of being "lost in hyperspace" is well known for long time. The loss of orientation occurs, in addition to other causes, as a result of inability to capture the link semantics while following the hypertext links. Furthermore, the links as we know them from the Web are single directional, so users lose their context immediately after following the link. The web pages appear from "nowhere" and disappear somewhere again after reading.
Several methods for navigation support have been proposed. Their common drawback is that they can not be used for inter-site navigation support, the only inter-site navigation aids being those offered by web browsers.
Results
We have proposed a method of adaptive navigation support in information spaces represented as graphs. In every step of navigation, adjacent nodes are extracted, evaluated using specified metrics and sorted according to computed evaluation.
With the aim of evaluation of the proposed method, the method has been implemented in the domain of navigation support in the Web. Graphical user interface of the implemented application is shown below. Navigation support is offered in terms of visualization of currently displayed web page neighborhood.
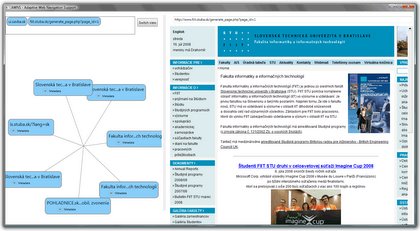
Evaluation metrics take user preferences captured by their tag usage into account. Web pages are also ranked based on their mutual similarity computed using common tags describing these sites in social bookmarking services (e.g. del.icio.us).
The implemented application has been evaluated by means of a user study. After a short browsing session, users have filled a survey. Generally, users perceived the application to be useful and easy to use, which was in accordance with the hypotheses. The main perceived advantage of the application is the ability to find new interesting web pages.
Conclusion
Compared to existing approaches, the advantage of the proposed method is inter-page navigation support which is not dependent on any navigational aids on the side of browsed hypertext. Constraints of the proposed method are mainly technological, given that while it is a trivial task to extract outgoing links from pure HTML (href tags), the problem is more difficult in case of various client side technologies as Flash or AJAX powered dynamically updated pages.
Publications
- Tomša, M.
- Adaptive Navigation Support in Open Spaces. Master thesis, Slovak University of Technology in Bratislava 2008.
 pdf (in Slovak)
pdf (in Slovak)
- Tomša, M., Bieliková, M.
- Hyperlinks Visualization using Social Bookmarking. In Proc. of the Nineteenth ACM Conf. on Hypertext and Hypermedia, HT'08, Pittsburgh, PA, USA, ACM, New York, NY, pp. 245-246.
| to Homepage | to Teaching | to the Top |
|
||
|
||