|
Source Code Search within Context Pavol Zbell Bachelor thesis project supervised by prof. Mária Bieliková, advised by Eduard Kuric |
Motivation
Search in source code is a necessary part of the daily work of most programmers. Programmers often search and explore source code to enrich their existing knowledge of the workings and functionality of a software system, or to get answers to questions about software evolution tasks they are currently working on, or they search for source code fragments that they could reuse. Research in this area focuses mainly on concept location – a process of identifying an initial location in the source code that implements functionality in a software system.
Built-in search tools available in IDEs which programmers use usually return a list of functions relevant to specified queries and programmers try to locate desired concept by jumping through functions based on the function calls they see. This approach is generally considered ineffective as it is usually resource and time consuming.
Our project is part of the research project PerConIK (Personalized Conveying of Information and Knowledge).
Method
In our work we focus on searching the source code in terms of concept location. We propose a method which takes changes over time to fine-grained elements (functions) of the source code into account. We assume that changes made at a particular time are related, and may represent a concept of the software system. Our approach to concept location is illustrated in the figure below.
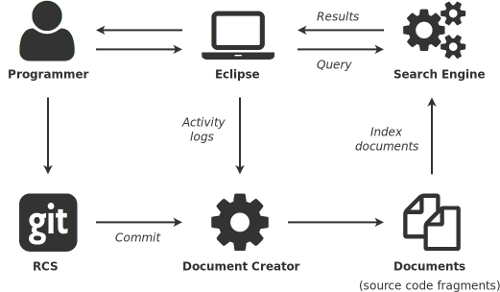
First we watch how programmers modify the source code in IDE and how they contribute these modifications to the RCS system. Then the document creator takes activity logs containing sequences of changes over time made to the source code elements and maps them to corresponding commits obtained from the RCS system. The document creator then produces documents representing source code elements in particular time. The documents containing commit metadata, the original source code and the nearest comments are indexed by the search engine. As long as searching in the source code is not the same as searching in plain text, proper indexing is achieved by extracting identifiers from the source code and tokenizing them using the INTT (Identifier Name Tokenization Tool). Above mentioned steps are continually repeated during programming.
Programmers are able to search in and explore the documents directly from the IDE interface. The performed source code search is based on simple vector space model, TF-IDF weighting scheme and cosine similarity between terms from programmer's query and terms extracted from the documents – source code elements (identifiers and comments).
Conclusion
We believe that developers using our method will gain a better tool for exploring the source code, and a better overview of the source code evolution and concepts of the software system. They will not need to jump between function calls because they will be able to see the whole evolution of the desired concept.
Publications
- Zbell, P.
- Source Code Search within Context. Bachelor thesis, Slovak University of Technology in Bratislava 2010. 41p.
 pdf (in Slovak)
pdf (in Slovak)
| to Homepage | to Teaching | to the Top |
|
||
|
||